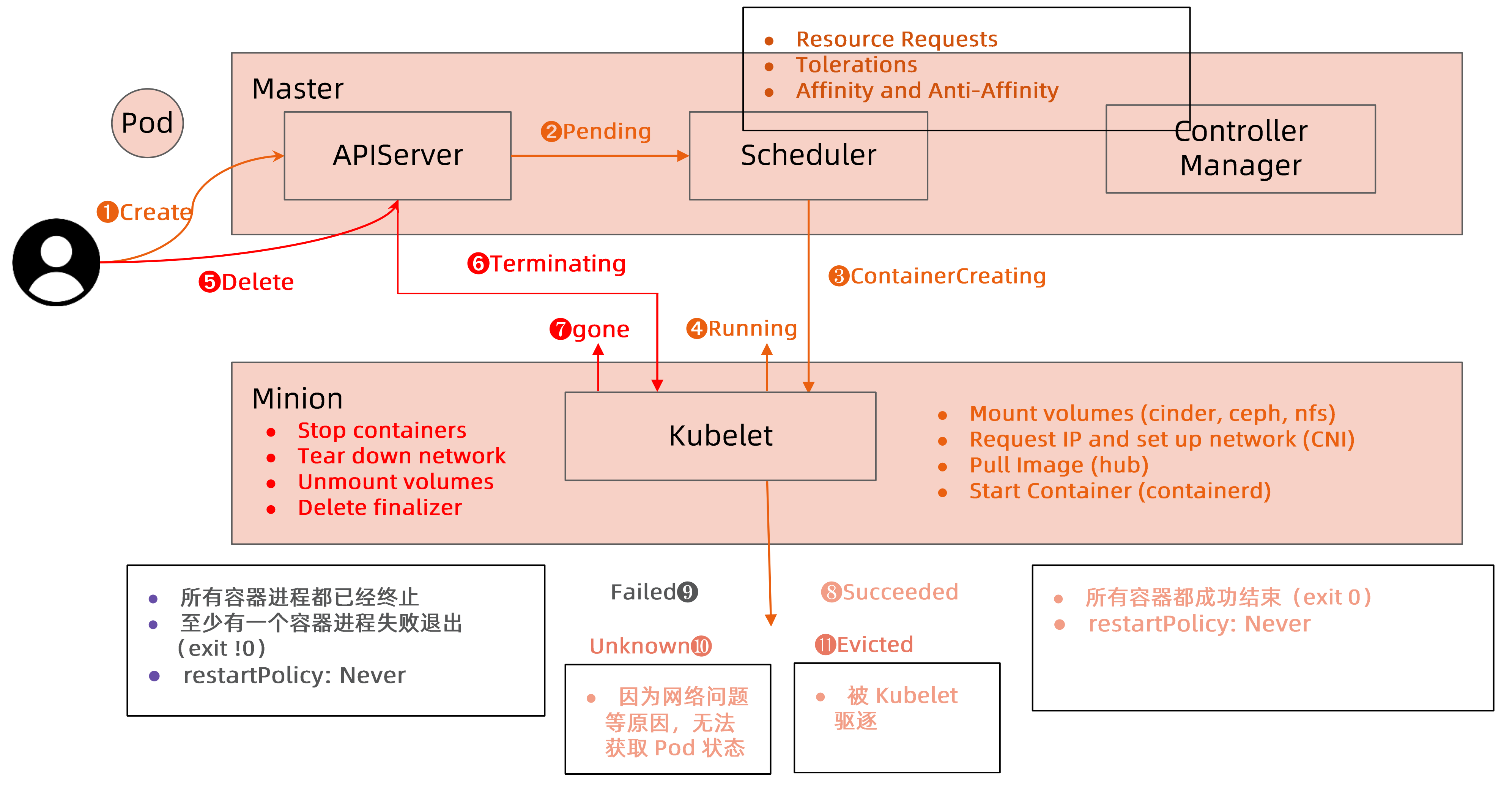
Pod Phase
pod运行阶段
- Pending
- Running
- Succeeded
- Failed
- Unknown
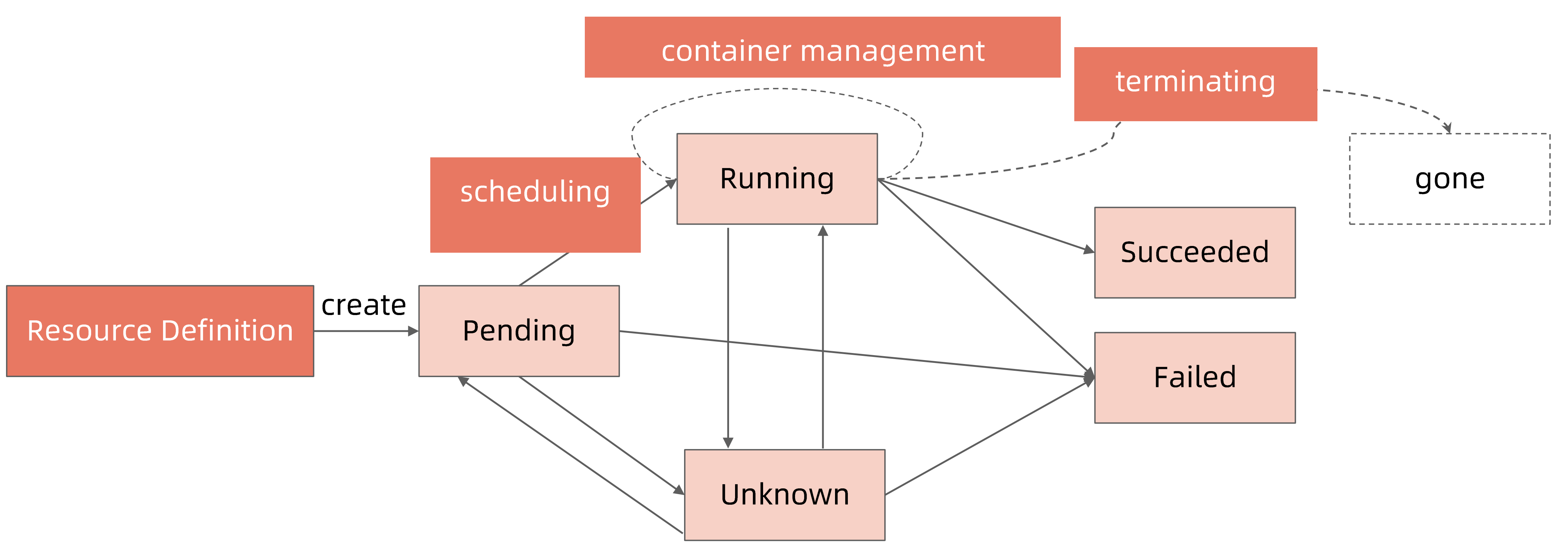
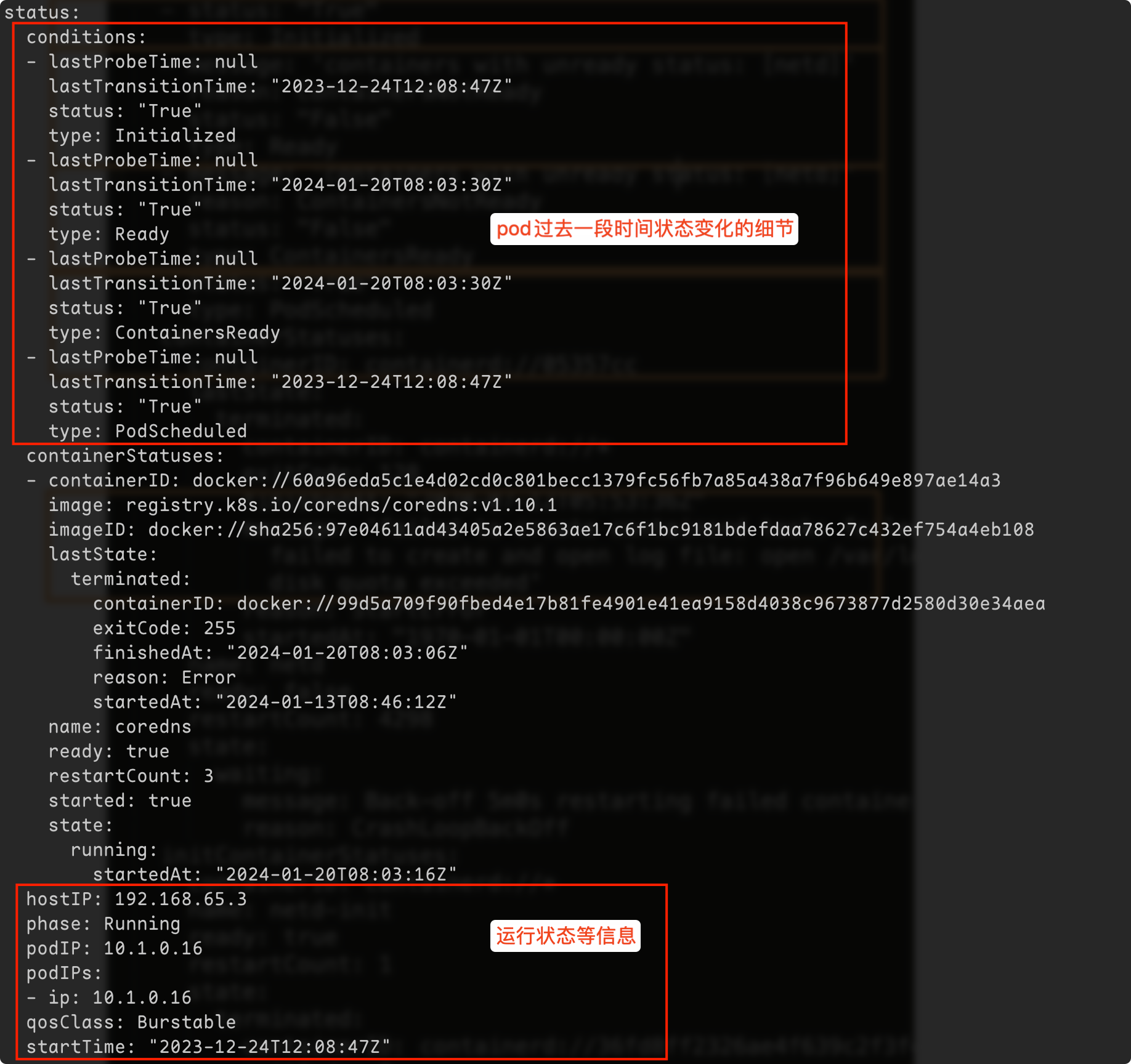
kubectl get pod显示的状态信息是由 podstatus的 conditions 和 phase 计算出来的
查看 Pod 细节: kubectl get pod $podname -oyaml
查看 Pod 相关事件: kubectl describe pod
pod状态计算细节:
| kubectl get pod返回的状态 | pod phase | conditions |
|---|---|---|
| Completed | Succeeded | |
| ContainerCreating | Pending | |
| CrashLoopBackOff | Running | Conainer exits |
| CreateContainerConfigError | Pending | configmap "xx" not foun secret "xx" not found |
| ErrImagePul/ImagePullBackOff/Init:ImagePullBackOff/InvalidImageName | Pending | Back-off pulling image |
| Error | Failed | restartPolicy:Never container exits with Error(not 0) |
| Evicted | Failed | message: "Usage ot EmptyDirvolume "myworkdir" exceeds thelimit "40Gi".' reason: Evicted |
| Init:0/1 | Pending | Init contianers don’t exist |
| Init:CrashLoopBackOff/Init:Error | Pending | Init container crashed(exit with not 1) |
| OOMKilled | Running | Containers are OOMKilled |
| StartError | Running | Containers cannot be started |
| Unknown | Running | Node NotReady |
| OutOfCpu/OutOfMemory | Failed | Scheduled, but it cannot pass kubelet admit |
如何保证Pod的高可用
避免容器进程被终止避免Pod被驱逐
- 设置合理的resouces.memory limits防止容器进程被OOMKill;
- 设置合理的emptyDir.sizeLimit并且确保数据写入不超过emptyDir的限制,防止pod被驱逐
Pod的QoS分类
- Guaranteed:
- pod的每个容器都设置了资源CPU和内存需求
- Limits和requests的值完全一致
- Burstable:
- 至少有一个容器制定了CPU或者内存request
- Pod的资源需求不符合Gauranteed QoS的条件,也就是requests和limits不一致
- BestEffort:
- Pod中的所有容器都未指定CPU或者内存资源需求requests
当计算节点检测到内存压力时,kubernets会按照BestEffort->Burstable->Guaranteed的顺序依次驱逐Pod
$ kubectl get pod xxxx -o yaml | grep qosClass
qosClass: Burstable定义 Guaranteed 类型的资源需求来保护你的重要 Pod.
认真考量 Pod 需要的真实需求并设置 Limit 和 resource,这有利于将集群资源利用率控制在合理范围并减少 Pod 被驱逐的现象。
尽量避免将生产 Pod 设置为 BestEffort,但是对测试环境来讲,BestEffort Pod 能确保大多数应用不会因为资源不足而处于 Pending 状态。
Tip
Burstable适用于大多数的场景,既可以超售,又可以锁定一定的资源
基于Taint的Evictions
NotReady Node被打上的Taint:
taints:
- effect: NoSchedule
key: node.kubernetes.io/unreachable
timeAdded: '2020-07-09T11:25:10Z'
- effect: NoExecute
key: node.kubernetes.io/unreachable
timeAdded: '2020-07-09T11:25:21Z'
- effect: NoSchedule
key: node.kubernetes.io/not-ready
timeAdded: '2020-07-09T11:24:28Z'
- effect: NoExecute
key: node.kubernetes.io/not-ready
timeAdded: '2020-07-09T11:24:32Z'节点临时不可达:
- 网络分区
- kubelet,containerd不工作
- 节点重启时间超过了15分钟
k8s默认给pod打上的toleration:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300增大tolerationSeconds以避免被驱除,特别是依赖于本地存储状态的有状态应用
健康检查探针
健康探针类型分为:
- livenessProbe: 探活,当检查失败时,意味着该应用进程已经无法正常提供服务,kubelet 会终止该容器进程并按照
restartPolicy决定是否重启。 - readinessProbe: 就绪状态检查,当检查失败时,意味着应用进程正在运行,但因为某些原因不能提供服务,Pod 状态会被标记为 NotReady。
- startupProbe: 在初始化阶段(Ready 之前)进行的健康检查,通常用来避免过于频繁的监测影响应用启动。
探测方法包括:
- ExecAction:在容器内部运行指定命令,当返回码为Q时,探测结果为成功。
- TCPSocketAction:由 kubelet 发起,通过TCP 协议检查容器 1P 和端口,当端口可达时,探测结果为成功。
- HTTPGetAction:由 kubelet 发起,对Pod 的IP 和指定端口以及路径进行HTTPGet 操作,当返回码为200-400之间时,探测结果为成功。
探针属性
| parameters | Description |
|---|---|
| initialDelaySeconds | Defaults to 0 seconds. Minimum value is 0 |
| periodSeconds | Default to 10 seconds. Minimum value is 1. |
| timeoutSeconds | Defaults to 1 second. Minimum value is 1. |
| successThreshild | Defaults to 1. Must be 1 for liveness. Minimum value is 1. |
| failureThreshold | Defaults to 3. Minimum value is 1. |
ReadinessGates
当除了pod自身的状态,还需要一些额外的操作(例如去其他地方配置dns)才能让pod就绪
- Readiness 允许在 Kubernetes自带的 Pod Conditions 之外引 入自定义的就绪条件。
- 新引入的 readinessGates condition 需要为 True 状态后, 加上内置的 Conditions, Pod才可以为就绪状态。
- 该状态应该由某控制器修改。
kind: Pod
...
spec:
readinessGates:
- conditionType: www.example.com/feature-1
status:
conditions:
- type: Ready
status: 'False'
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: www.example.com/feature-1
status: 'False' # 需要由额外的readinessGates控制器来修改状态
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: ContainersReady
status: 'True'
lastProbeTime: null
lastTransitionTime: '2020-06-23T10:02:57Z'
containerStatuses:
- containerID: ...
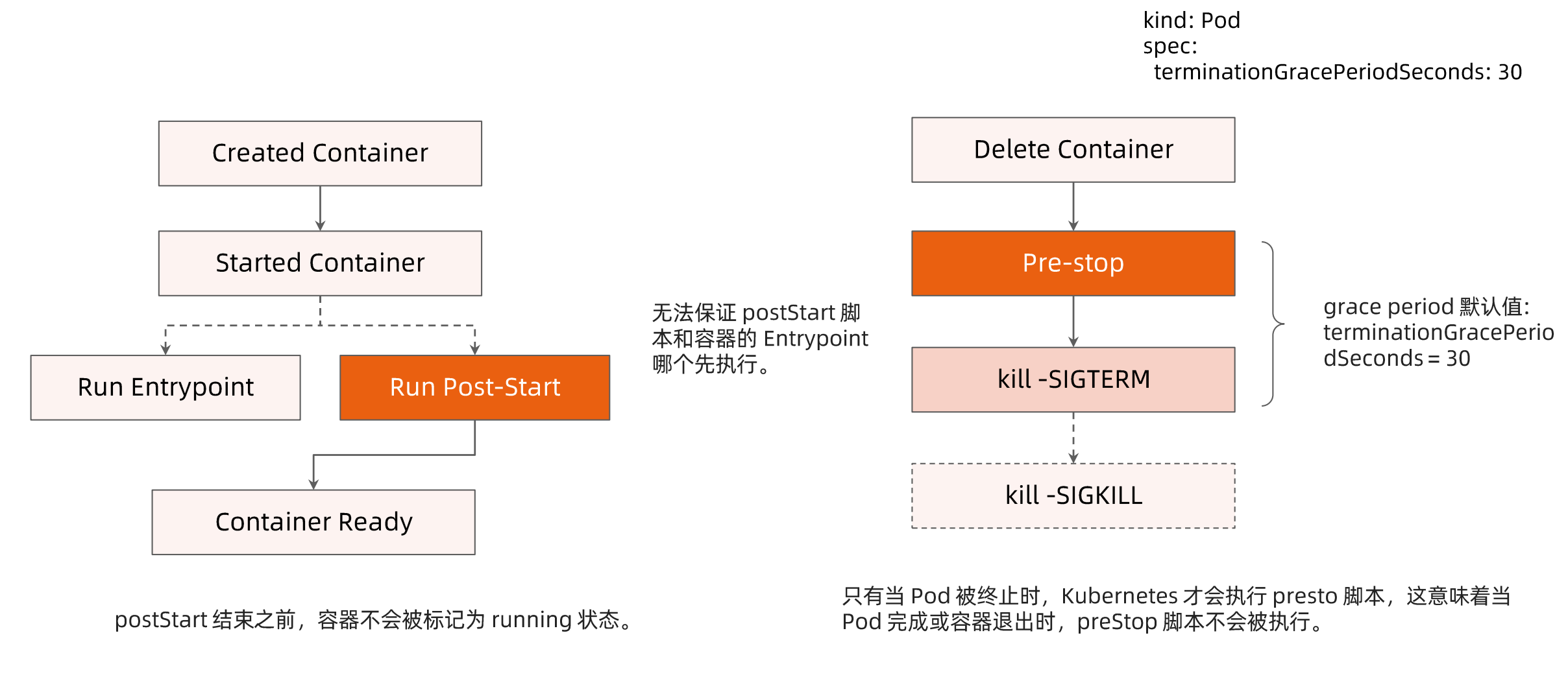
ready: truePost-start和Pre-Stop Hook
post-start script: 启动容器后,需要一些额外的启动后操作 pre-stop script: pod被终止时,会先执行pre-stop script,例如可以定义优雅终止的行为
Caution
其中几个注意点
- entrypoint和post-start scritp无法保证智行的顺序先后
- kubelet终止pod的时候会有三个动作,pre-stop -> kill -SIGTERM -> kill -SIGKILL
- 只有pod被终止时,才会执行pre-stop script,意味着当pod完成或者容器退出时,pre-stop script不会被智行
- 默认的pre-stop script和kill -SIGTERM的时间为30s, 超过时间后会直接kill -SIGKILL

案例
initial-delay
readinessProbe默认是不ready的
apiVersion: v1
kind: Pod
metadata:
name: initial-delay
spec:
containers:
- name: initial-delay
image: centos
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 30
periodSeconds: 5liveness
对于livenessProbe默认是live的,如果后面发现没有live,才会变更状态
apiVersion: v1
kind: Pod
metadata:
name: liveness1
spec:
containers:
- name: liveness
image: centos
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5readiness
apiVersion: v1
kind: Pod
metadata:
name: http-probe
spec:
containers:
- name: http-probe
image: nginx
readinessProbe:
httpGet:
# ## this probe will fail with 404 error code
# ## only httpcode between 200-400 is retreated as success
path: /healthz
port: 80
initialDelaySeconds: 30
periodSeconds: 5
successThreshold: 2readiness-gate
apiVersion: v1
kind: Pod
metadata:
labels:
app: readiness-gate
name: readiness-gate
spec:
readinessGates:
- conditionType: www.example.com/feature-1
containers:
- name: readiness-gate
image: nginx
---
apiVersion: v1
kind: Service
metadata:
name: readiness-gate
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: readiness-gate
post-start
apiVersion: v1
kind: Pod
metadata:
name: poststart
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: [/bin/sh, -c, echo Hello from the postStart handler > /usr/share/message]pre-stop
apiVersion: v1
kind: Pod
metadata:
name: prestop
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
preStop:
exec:
command: [/bin/sh, -c, nginx -s quit; while killall -0 nginx; do sleep 1; done]no-sigterm
apiVersion: v1
kind: Pod
metadata:
name: no-sigterm
spec:
# 设置发送sigterm后60s再发送sigkill
terminationGracePeriodSeconds: 60
containers:
- name: no-sigterm
image: centos
command: [/bin/sh]
args: [-c, while true; do echo hello; sleep 10;done]terminating pod的经验分享
- bash/sh 会忽略SIGTERM的信号,因此
kill -SIGTERM会永远超时,若应用用bash/sh作为entrypoint,则应该避免过长时间的grace period - 如果希望快速终止应用进程,可以采取如下方案:
- 在pre-stop script中主动退出进程
- 在主容器进程中使用特定的初始化进程
- 优雅的初始化进程应该:
- 正确处理系统信号量,将信号量转发给子进程
- 在主进程退出之前,需要先等待并确保所有子进程退出
- 监控并清理孤儿子进程
- 参考: tini
数据应该如何存储
| 存储卷类型 | 容器重启后是否存在 | pod重建后数据是否存在 | 是否有大小控制 | 注意 |
|---|---|---|---|---|
| emptyDir | 是 | 否 | 是 | |
| hostPath | 是 | 否 | 否 | 需要额外的权限控制 |
| Local volume | 是 | 否 | 是 | 无备份 |
| Network volume | 是 | 是 | 是 | |
| rootFS | 否 | 否 | 否 | 不要写任何数据 |
Caution
注意: 控制日志写入速度,防止操作系统在配置日志滚动窗口期内把硬盘写满
容器应用可能面临的进程中断
| 类型 | 影响 | 建议 |
|---|---|---|
| kubelet升级 | * 不重建容器 | 无影响 |
| kubelet升级 | _ 重建容器 _ pod进程会被重启 | _ 冗余部署 _ 跨故障域部署 |
| 主机操作系统升级节点手工重启 | _ 节点重启 _ pod进程会被终止数分钟(10分钟左右) | _ 跨故障域部署 _ 增加liveness、readiness探针 设置合理的低NotReady node的Toleration时间 |
| 节点下架、送修 | _ 节点会drain,重启或者从集群中删除 _ pod进程会被终止数分钟 | _ 跨故障域部署 _ 利用pod distruption budge避免节点被drain导致Pod被意外删除而影响业务 * 利用pre-stop script做数据备份等操作 |
| 节点崩溃 | * pod进程会被终止15分钟左右 | * 跨故障域部署 |
