计算节点相关、操作系统选择
通用操作系统
- Ubuntu
- Centos
- Fedora
专为容器优化的操作系统
- CoreOS
- RedHat Atomic
- Snappy Ubuntu Core
- RancherOS
云原生的原则
- 在灾难发生的时候,难以重新构建服务。持续过多的手工操作,缺乏记录,会导致很难由标准初始化后的服务器来重新构建起等效的服务。
- 在服务运行过程中,持续的修改服务器,就犹如程序中的可变变量的值发生变化而引入的状态不一致的并发风险。这些对于服务器的修改,同样会引入中问状态,从而导致不可预知的问题。
- 不可变的容器镜像
- 不可变的主机操作系统
- 只安装必要的工具(支持系统运行的最小工具集)
- 任何调试工具、例如性能排查、网络排查,均可以后期以容器形式运行
操作系统构建流程
- 通过rpm-ostree将rpm包编译成ostree的格式,只保证基本的操作系统镜像,保持一个最小的集合
- 辅助类的工具通过
docker build构建成docker镜像
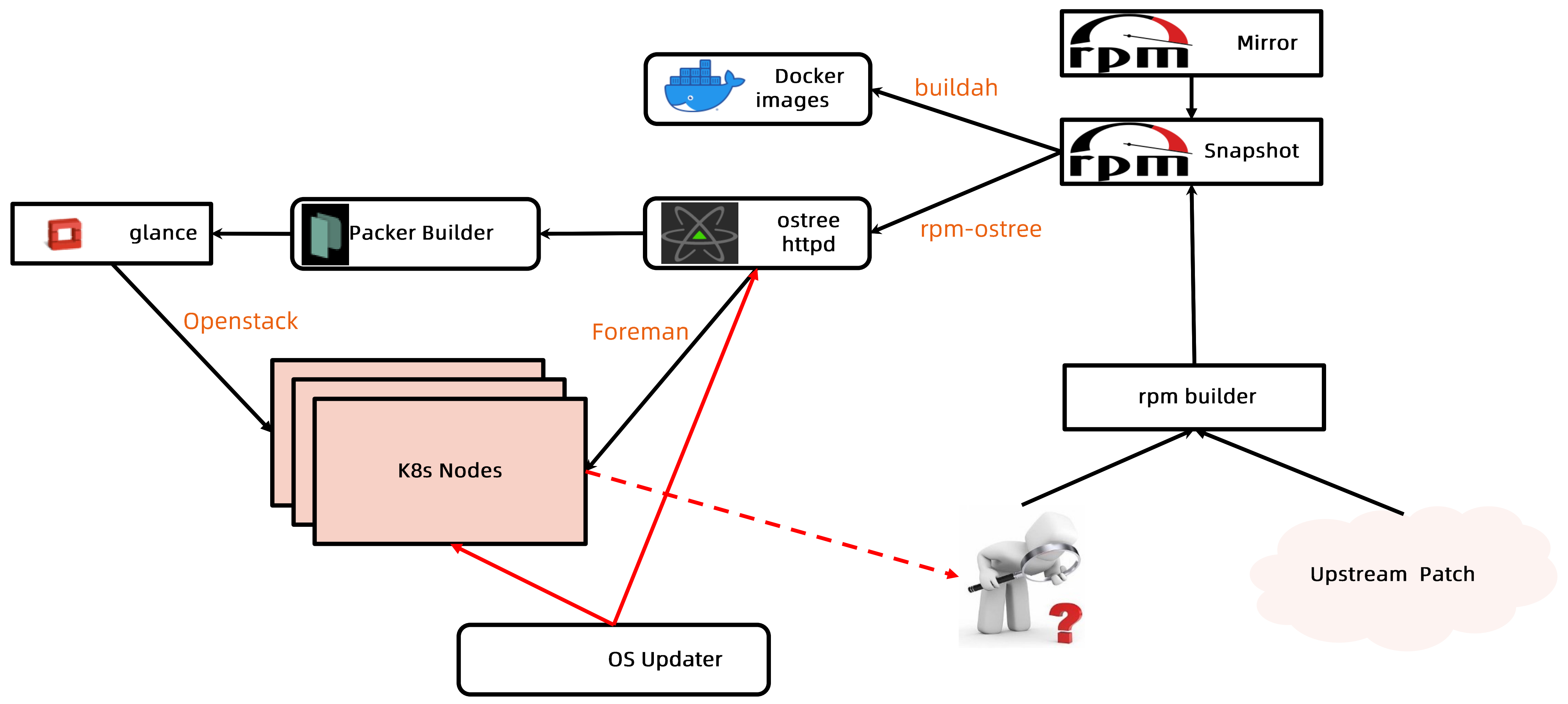
- 针对Bare Metal中存在kickstart,kickstart中可直接调用ostree来加载操作系统,完成操作系统的启动
- 针对虚拟机,通过package builder把ostree构建成一个个存在glance的操作系统镜像,最终openstack在启动虚机的时候会读取这些镜像
ostree
提供一个共享库(libostree)和一些列命令行 提供与git命令行一致的体验,可以提交或者下载一个完整的可启动的文件系统树 提供将ostree部署进 bootloader的机制
参考: module-setup.sh
构建ostree
- rpm-ostree 基于treefile将rpm包构建成ostree,管理ostree以及bootloader配置
- treefile
- refer: 分支名(版本,cpu架构)
- repo: rpm package repositories
- packages: 待安装组件

将rpm构建成ostree: rpm-ostree compose tree --unified-core --cachedir=cache --repo=./build-repo /path/to/treefile.json
加载ostree
初始化项目
ostree admin os-init centos-atomic-host导入ostree repo
ostree remote add atomic http://ostree.svr/ostree拉取ostree
ostree pull atomic centos-atomic-host/8/x86_64/standard部署os
ostree admin deploy --os=centos-atomic-host centos-atomic-host/8/x86_64/standard --karg='root=/dev/atomicos/root'
操作系统加载
- 物理机
- 物理机通常通过foreman启动,foreman通过pxe boot,并加载kickstart
- kickstart通过
ostree deploy即可完成操作系统部署
- 虚拟机
- 需要通过镜像工具package builder将ostree构建成qcow2格式,vhd,raw等模式
节点资源管理
NUMA Node
Non-Uniform Memory Access是一种内存访问方式,是为多处理器计算机设计的内存架构
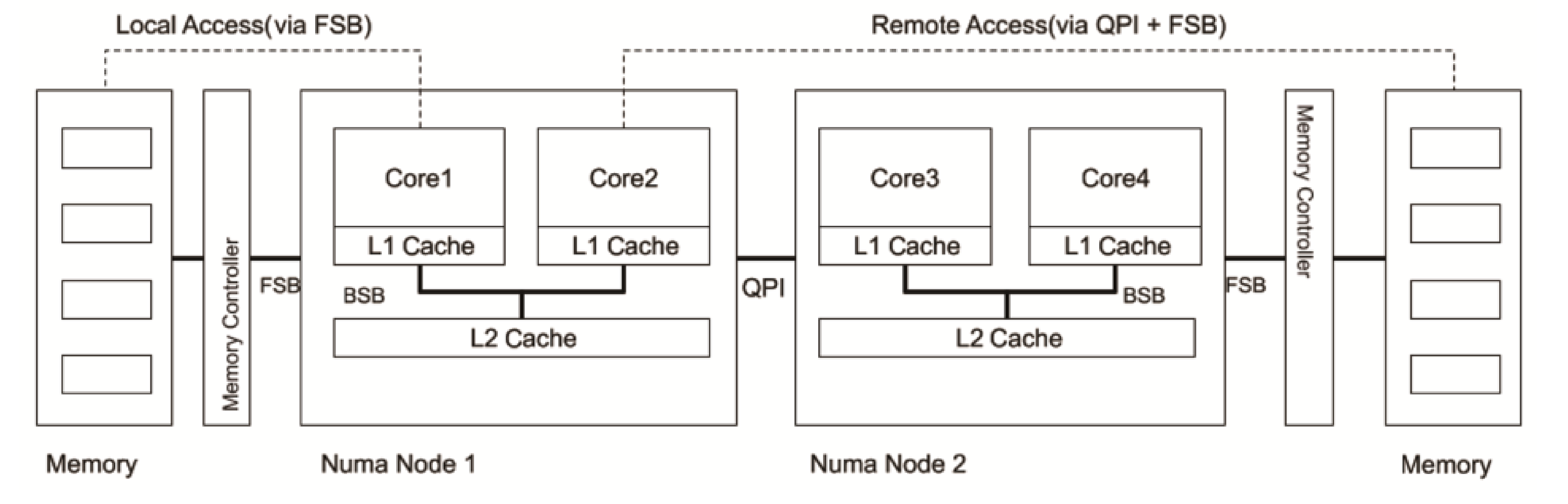
- 本地内存访问通过FSB(front service bus)
- 远端内存访问通过QPI(quick path interconnect) + FSB
状态上报
- 节点基础信息,包括IP 地址、操作系统、内核、运行时、kubelet、kube-proxy版本信息。
- 节点资源信息包括CPU、内存、HugePage、临时存储、GPU等注册设备,以及这些资源中可以分配给容器使用的部分。
- 调度器在为Pod选择节点时会将机器的状态信息作为依据。
| 状态 | 状态的意义 |
|---|---|
| Ready | 节点是否健康 |
| MemoryPressure | 节点是否存在内存压力 |
| PIDPressure | 节点是否存在比较多的进程 |
| DisPressure | 节点是否存在磁盘压力 |
| NetworkUnavailable | 节点网络配置是否正确 |
Lease对象
早期kubelet的状态上报直接更新node对象,而上报的信息包括状态信息和资源信息,因此需要传输的数据包较大,给APIServer和etcd造成比较大的压力
,在默认的40s的`nodeLeaseDurationSeconds`周期内,若Lease对象没有被更新,可通过命令kubectl get lease -n kube-node-lease -oyaml查看
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: '2021-08-19T02:50:09Z'
name: k8snode
namespace: kube-node-lease
ownerReferences:
- apiVersion: v1
kind: Node
name: k8snode
uid: 58679942-e2dd-4ead-aada-385f099g5f56
resourceVersion: '1293702'
uid: 1bf51951-b832-49da-8708-4b224blec3ed
spec:
holderIdentity: k8snode
leaseDurationSeconds: 40
renewTime: '2021-09-08T01:34:16.489589Z'资源管理
计算节点除用户容器外,是存在很多支撑系统运行的基础服务,例如systemd、journald、sshd、dockerd、containerd、kubelet等
为了使服务进程能够正常运行,要确保他们在任何时候都可以获取足够的系统资源,所以我们要为这些系统进程预留资源
kubelet可通过众多启动参数为系统预留CPU、内存、PID等资源,比如SyetemReserved、KubeReserved等
Capacity和Allocatable
容量资源(Capacity)是指 kubelet 获取的计算节点当前的资源信息。
- CPU 是从
/proc/cpuinfo文件中获取的节点CPU核数 - memory 是从
/proc/memoryinfo中获取的节点内存大小 - ephemeral-storage是指节点根分区的大小。
资源可分配额(Allocatable)是用户Pod可用的资源,是资源容量减去分配给系统的资源的剩余部分。
allocatable:
cpu: '24'
ephemeral-storage: 205838Mi
memory: 177304536Ki
pods: '110'
capacity:
cpu: '24'
ephemeral-storage: 205838Mi
memory: 179504088Ki
pods: '110'资源可用额监控
- kubelet依赖内嵌的开源软件cAdvisor,周期性检查节点资源使用情况
- CPU是可压缩资源,根据不同进程分配时间配额和权重,CPU可被多个进程竞相使用
- 驱逐策略是基于磁盘和内存资源用量进行的,因为两者属于不可压缩的资源,当此类资源使用耗尽使将无法再申请
| 检查类型 | 说明 |
|---|---|
| memroy.available | 节点当前的可用内存 |
| nodefs.available | 节点根分区的可使用磁盘大小 |
| nodefs.inodesFree | 节点根分区的可使用inode |
| imagefs.inodesFree | 节点运行时分区的可使用inode |
| imagefs.available | 节点运行时分区的可使用磁盘大小 节点如果没有运行时分区,就不会有相应的资源监控 |
驱逐策略
- kubelet会在系统资源不足时终止一些容器进程,以空出系统资源,保证节点的稳定性
- kubelet发起的驱逐只停止pod的所有容器进程,并不会直接删除pod
- pod的
status.phase会被标记为Failed status.reason会被设置为Evictedstatus.message则会记录被驱逐的原因
- pod的
kubelet获得节点的可用额信息后,会结合节点的容量信息来判断当前节点运行的Pod是否满足驱逐条件。
驱逐条件可以是绝对值或百分比,当监控资源的可使用额少于设定的数值或百分比时,kubelet就会发起驱逐操作。
kubelet参数evictionMinimumReclaim可以设置每次回收的资源的最小值,以防止小资源的多次回收。
| kubelet参数 | 分类 | 驱逐方式 |
|---|---|---|
| evicitonSoft | 软驱逐 | 当检测到当前资源达到软驱逐的阈值时,并不会立即启动驱逐操作,而是要等待一个宽限期 这个宽限期选取 EvictionSoftGracePeriod和Pod指定的TerminationGracePeriodSeconds中较小的值 |
| evictionHard | 硬驱逐 | 没有宽限期,一旦检测到满足硬驱逐的条件,就直接终止容器来释放紧张资源 |
Eviction configuration
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: 500Mi
nodefs.available: 1Gi
imagefs.available: 100Gi
evictionMinimumReclaim:
memory.available: 0Mi
nodefs.available: 500Mi
imagefs.available: 2Gi基于内存压力的驱逐
memory.available表示了当前系统的可用内存情况
kubelet默认设置了memory.available<100Mi的硬驱逐条件
当kubelet检测到当前节点可用内存资源紧张并满足驱逐条件时,会将节点的MemoryPressure状态设置为True,调度器会阻止BestEffort Pod调度到内存承压的节点
kubelet启动对内存不足的驱逐操作时,会按照如下的顺序选择目标pod:
- 判断pod所有容器的内存使用量总和是否超出了请求的内存量,超出请求资源的pod会成为备选目标
- 查询pod的调度优先级,低优先级的pod被优先驱逐
- 计算pod所有容器的内存收用量和pod请求的内存量的差值,差值越小,越不容易被驱逐
基于磁盘压力的驱逐
- nodefs.available
- nodefs.inodesFree
- imagefs.available
- imagefs.inodefsFree
- 有容器运行时分区
- nodefs达到驱逐阈值,那么kubelet删除已经退出的容器
- imagefs达到驱逐阈值,那么kubelet删除所有未使用的镜像
- 无容器运行时分区
- kubelet同时删除未运行的容器和未使用的镜像
回收已经退出的容器和末使用的镜像后,如果节点依然满足驱逐条件,kubelet 就会开始驱逐正在运行的 Pod,进一步释放磁盘空间。
- 判断Pod的磁盘使用量是否超过请求的大小,超出请求资源的Pod会成为备选目标。
- 查询Pod的调度优先级,低优先级的 Pod 优先驱逐。
- 根据磁盘使用超过请求的数量进行排序,差值越小,越不容易被驱逐.
容器的Cgroup配置
CPU Cgroup配置
针对不同的QoS Class的Pod,kubernetes按照如下Hierarchy组织Cgroup中的CPU子系统
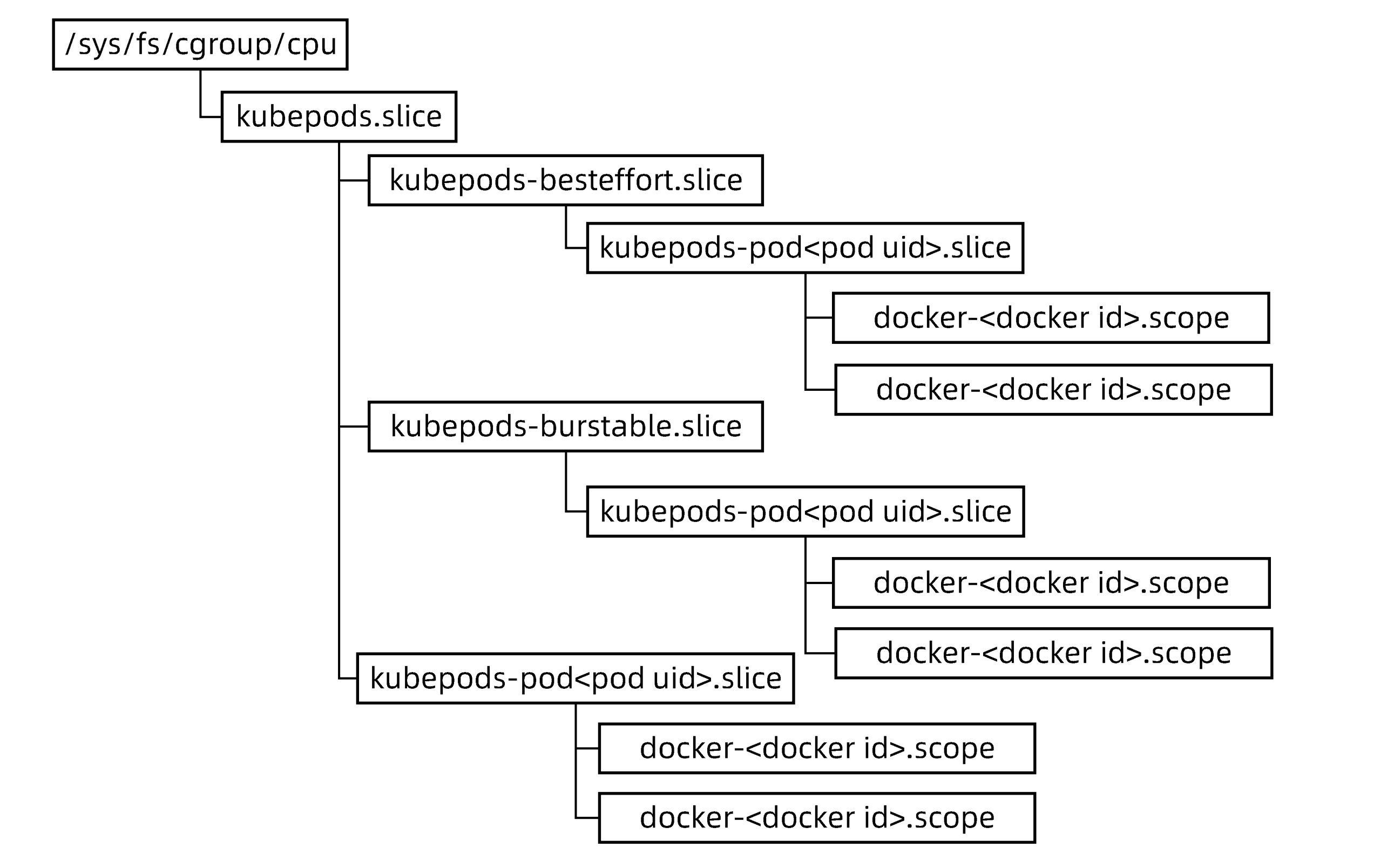
CPU Cgroup配置
| Cgroup类型 | 参数 | QoS类型 | 值 |
|---|---|---|---|
| 容器的Cgroup | cpu.shares | BestEffort | 2 |
| Burstable | requests.cpu*1024 | ||
| Guaranteed | requests.cpu*1024 | ||
| cpu.cfs_quota_us | BestEffort | -1 | |
| Burstable | limits.cpu*100 | ||
| Guaranteed | limits.cpu*100 | ||
| Pod的Cgroup | cpu.shares | BestEffort | 2 |
| Burstable | Pod中所有容器(requests.cpu*1024)之和 | ||
| Guaranteed | Pod中所有容器(requests.cpu*1024)之和 | ||
| cpu.cfs_quota_us | BestEffort | -1 | |
| Burstable | Pod中所有容器(limits.cpu*100)之和 | ||
| Guaranteed | Pod中所有容器(limits.cpu*100)之和 |
内存的Cgroup配置
针对不同的QoS Class的Pod,kubernetes按照如下Hierarchy组织Cgroup中的Memory子系统
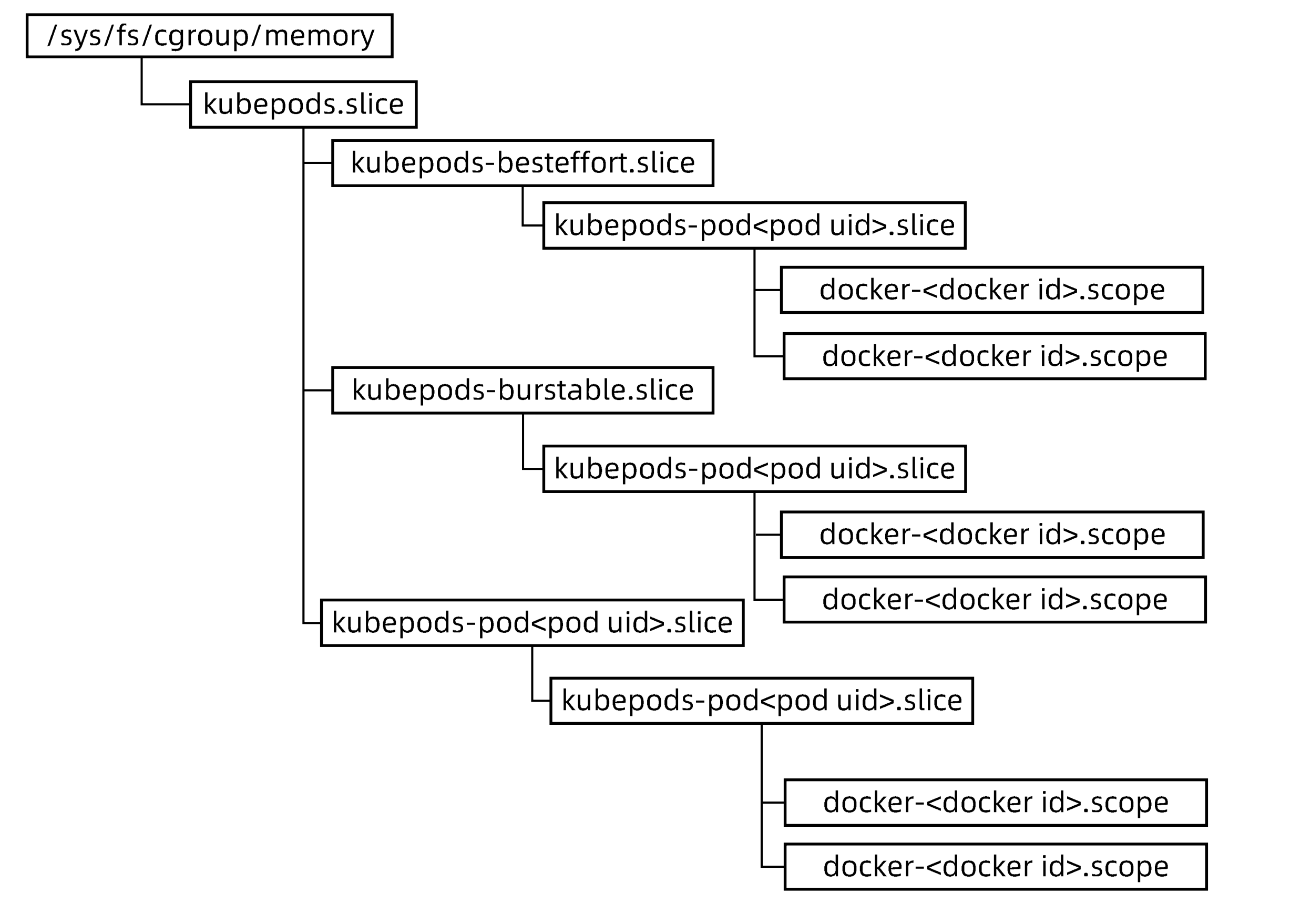
内存Cgroup配置
| Cgroup类型 | 参数 | QoS类型 | 值 |
|---|---|---|---|
| 容器的Cgroup | memory.limit_in_bytes | BestEffort | 9223372036854771712 |
| Burstable | limits.memory | ||
| Guaranteed | limits.memory | ||
| Pod的Cgroup | memory.limit_in_bytes | BestEffort | 9223372036854771712 |
| Burstable | 所有Pod容器(limits.memory)之和 | ||
| Guaranteed | 所有Pod容器(limits.memory)之和 |
OOM Killer行为
- 系统的OOM Killer可能会采取OOM的方式来中止某些容器的进程,进行必要的内存回收操作。
- 而系统根据进程的oom_score来进行优先级排序,选择待终止的进程,且进程的oom_score越高,越容易被终止。
- 进程的oom_score是根据当前进程使用的内存占节点总内存的比例值乘以10,再加上oom_score_adj综合得到的。
- 而容器进程的oom_score_adj正是kubelet裉据
memory.request进行设置的。
| Pod QoS类型 | oom_score_adj |
|---|---|
| Guaranteed | -997 |
| Burstable | min(max(2,1000-(1000*memoryRequestBytes)/machineMemoryCapacityBytes), 999) |
| BestEffort | 1000 |
查看pod的oom_score

其他资源管理
日志管理
- logrotate的执行周期不能过长,以防日志短时间内大量增长。
- 同时配置日志的rotate条件,在日志不占用太多空间的情况下,保证有足够的日志可供查看。
- Docker
- 除了基于系统logrotate管理日志,还可以依赖Docker自带的日志管理功能来设置容器日志的数量和每个日志文件的大小。
- Docker写入数据之前会对日志大小进行检查和rotate操作,确保日志文件不会超过配置的数量和大小。
- Containerd
- 日志的管理是通过 kubelet 定期(默认为10s)抗行 du命令,来检查容器日志的数量和文件的大小的。
- 每个容器日志的大小和可以保留的文件个数,可以通过 kubelet 的配置参数
container-log-max-size和container-log-max-files进行调整。
Docker卷管理
- 在构建容器镜像时,可以在Dockerfile中通过VOLUME指令声明一个存储卷,目前Kubernetes 尚末将其纳入管控范围,不建议使用。
- 如果容器进程在可写层或emptyDir卷进行大量读写操作,就会导致磁盘I/O 过高,从而影响其他容器进程甚至系统进程。
- Docker和Containerd运行时都基于Cgroup v1。对于块设备,只支持对Direct I/O限速,而对于Buffer I/O还不具备有效的支持。因此,针对设备限速的问题,目前还没有完美的解决方案,对于有特殊I/O需求的容器,建议使用独立的磁盘空间。
网络资源限制
可利用CNI社区提供的bandwith插件
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernets.io/ingress-bandwith: 10MB进程数限制
- kubelet通过系统调用周期性地获取当前系统的PID的使用量,并读取
/proc/sys/kernel/pid_max获取系统支持的PID上限。 - 如果当前的可用进程数少于设定阈值,那么kubelet会将节点对象的
PIDPressure标记为True。 - kube-scheduler在进行调度时,会从备选节点中对处于NodeUnderPIDPressure状态的节点进行过滤。
