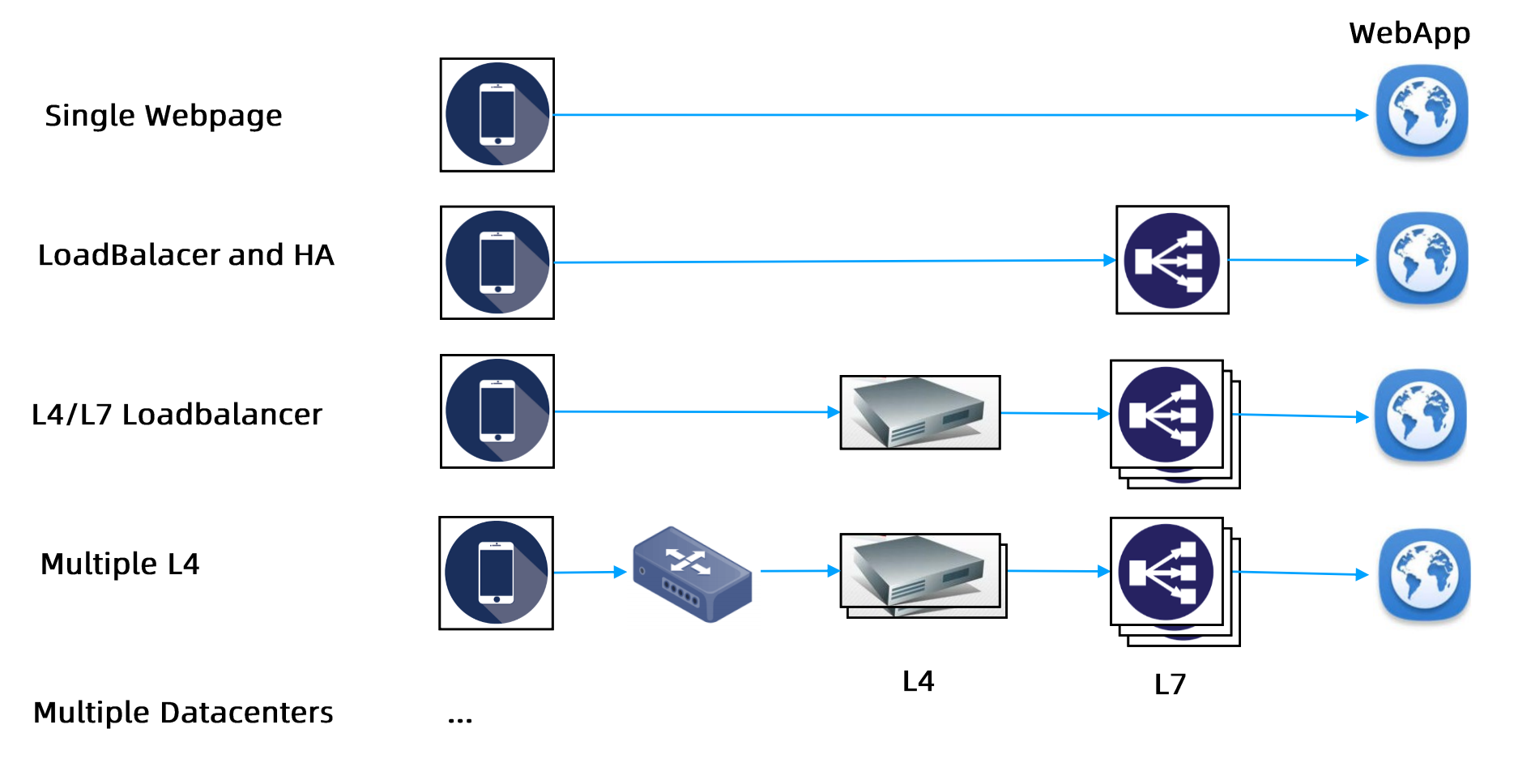
服务发现
- 微服务架构是由一系列职责单一的细粒度服务构成的分布式网状结构,服务之间通过轻量机制进行通信,这时候必然引入一个服务注册发现问题,也就是说服务提供方要注册通告服务地址,服务的调用方要能发现目标服务。
- 同时服务提供方一般以集群方式提供服务,也就引入了负载均衡和健康检查问题。
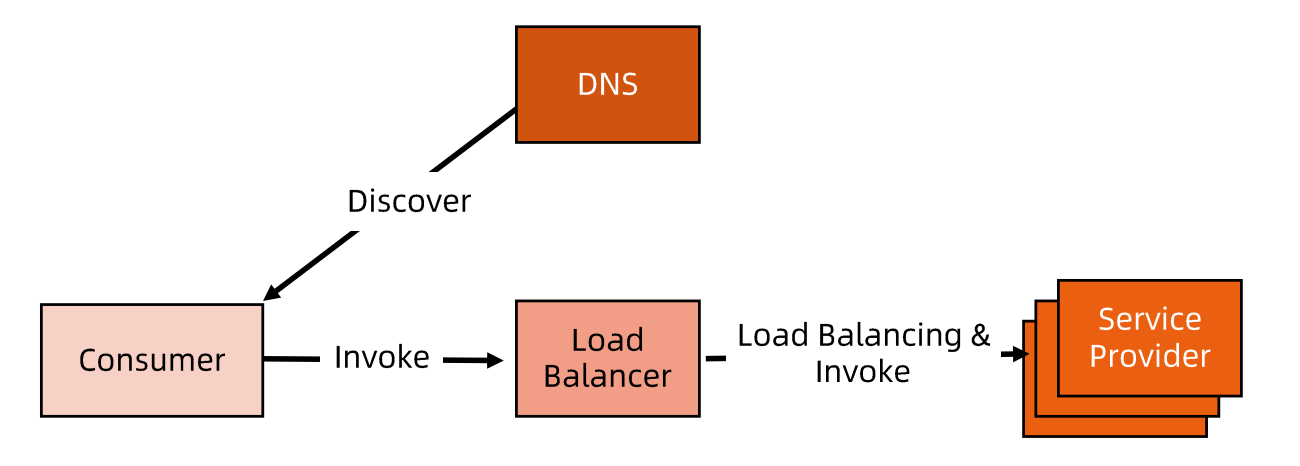
集中式LB服务发现
- 在服务消费者和服务提供者之间有一个独立的LB。
- LB上有所有服务的地址映射表,通常由运维配置注册。
- 当服务消费方调用某个目标服务时,它向LB发起请求,由LB以某种策略(比如Round-Robin做负载均衡后将请求转发到目标服务。
- LB一般具备健康检查能力,能自动摘除不健康的服务实例。
- 服务消费方通过 DNS 发现LB,运维人员为服务配置一个 DNS 域名,这个域名指向 LB。
- 集中式LB的主要问题是单点问题,所有服务调用流量都经过 LB,当服务数量和调用量大的时候,LB容易成为瓶颈,且一旦LB发生故障对整个系统的影响是灾 难性的。
- LB 在服务消费方和服务提供方之间增加了一跳(hop),有一定性能开销。
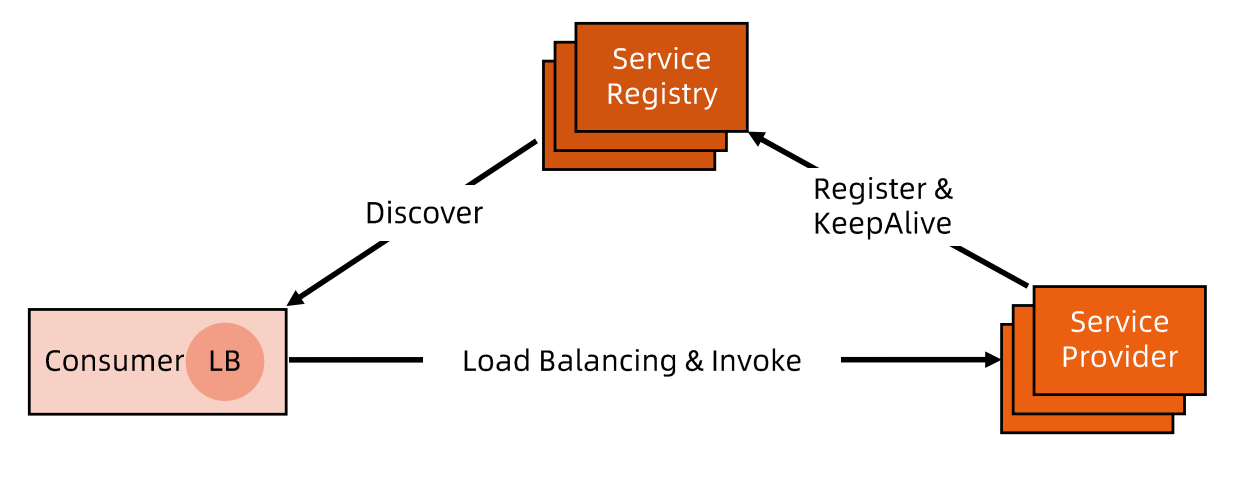
进程内LB服务发现
- 进程内LB方案将LB的功能以库的形式集成到服务消费方进程里头,该方案也被称为客户端负载方案。
- 服务注册表(Service Registry) 配合支持服务自注册和自发现,服务提供方启动时,首先将服务地址注册到服务注册表(同时定期报心跳到服务注册表以表明服务的存活状态)。
- 服务消费方要访问某个服务时,它通过内置的LB组件向服务注册表查询(同时缓存并定期刷新)目标服务地址列表,然后以某种负载均衡策略选择一个目标服务地址,最后向目标服务发起请求。
- 这一方案对服务注册表的可用性(Availability)要求很高,一般采用能满足高可用分布式一致的组件(例如ZooKeeper, Consul, etcd 等)来实现。
- 进程内 LB是一种分布式模式,LB 和服务发现能力被分散到每一个服务消费者的进程内部,同时服务消费方和服务提供方之间是直接调用,没有额外开销,性能比较好。该方案以客户库(Client Library)的方式集成到服务调用方进程里头,如果企业内有多种不同的语言栈,就要配合开发多种不同的客户端,有一定的研发和维护成本。
- 一旦客户端跟随服务调用方发布到生产环境中,后续如果要对客广库进行升级,势必要求服 务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。
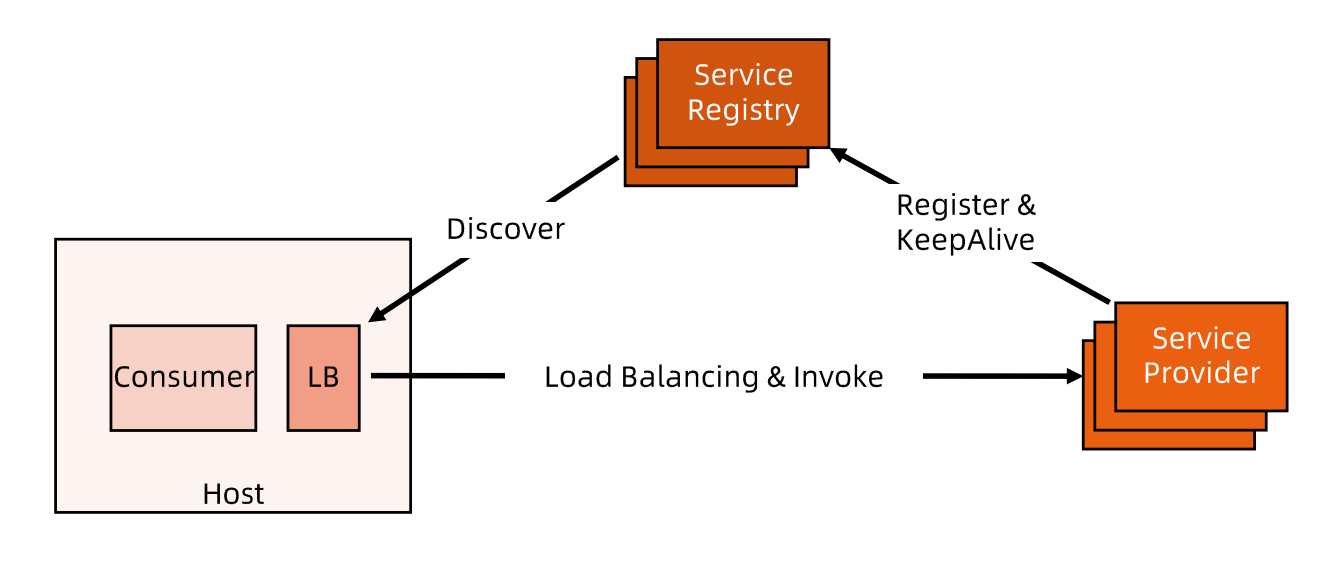
独立LB进程服务发现
- 针对进程内 LB 模式的不足而提出的一种折中方案,原理和第二种方案基本类似。
- 不同之处是,将 LB 和服务发现功能从进程内移出来,变成主机上的一个独立进程,主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立 LB进程做服务发现和负载均衡。
- LB 独立进程可以进一步与服务消费方进行解耦,以独立集群的形式提供高可用 的负载均衡服务。这种模式可以称之为真正的"软负载(Soft Load Balancing)"。
- 独立 LB 进程也是一种分布式方案,没有单点问题,一个 LB 进程挂了只影响该主机上的服务调用方。
- 服务调用方和LB之间是进程间调用,性能好。
- 简化了服务调用方,不需要为不同语言开发客户库,LB的升级不需要服务调用方改代码。
- 不足是部署较复杂,环节多,出错调试排查问题不方便。
负载均衡
- 纵向扩展,是从单机的角度通过增加硬件处理能力,比如 CPU 处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题;
- 横向扩展,通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力,这就是典型的集群和负载均衡架构。
- 解决并发压力,提高应用处理性能,增加吞吐量,加强网络处理能力;
- 提供故障转移,实现高可用;
- 通过添加或减少服务器数量,提供网站伸缩性,扩展性;
- 安全防护,负载均衡设备上做一些过滤,黑白名单等处理;
DNS 负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在 DNS服务器,配置多个 A记录,这些A记录对应的服务器构成集群。
| 优点 | 缺点 |
|---|---|
| - 负载均衡工作,交给DNS服务器处理,声调了负载均衡服务器维护的麻烦 - : 可以支持基于地址的域名解析,解析撑距离用户最近的服务器地址,可以加快访问速度,改善性能 | - DNS解析是多级解析,新增/修改DNS后,解析时间较长;解析过程中,用户访问网站失败; - DNS负载均衡的控制权在域名商,无法对其做更多的改善和扩展; - 也不能反映服务器的当前运行状态; 支持的算法少; 不能区分服务器的差异。不能根据系统与服务的状态来判 |
| 断负载 |
负载均衡技术概览

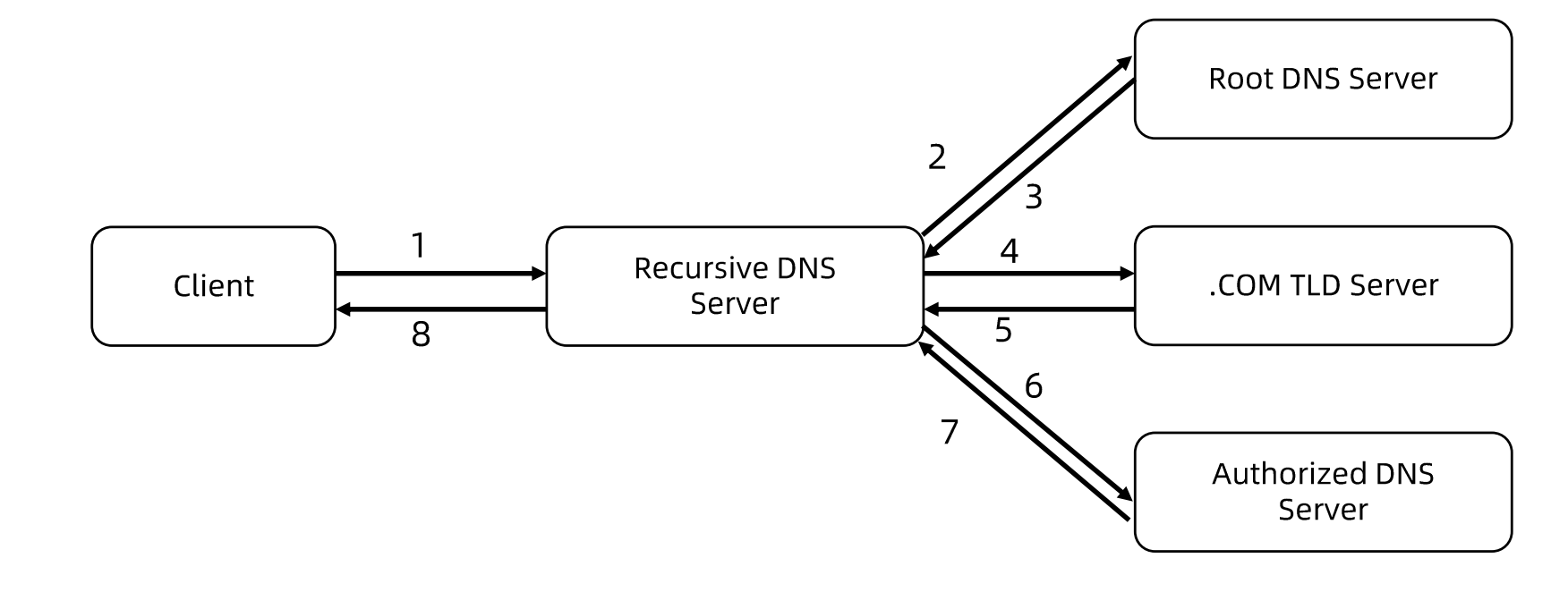
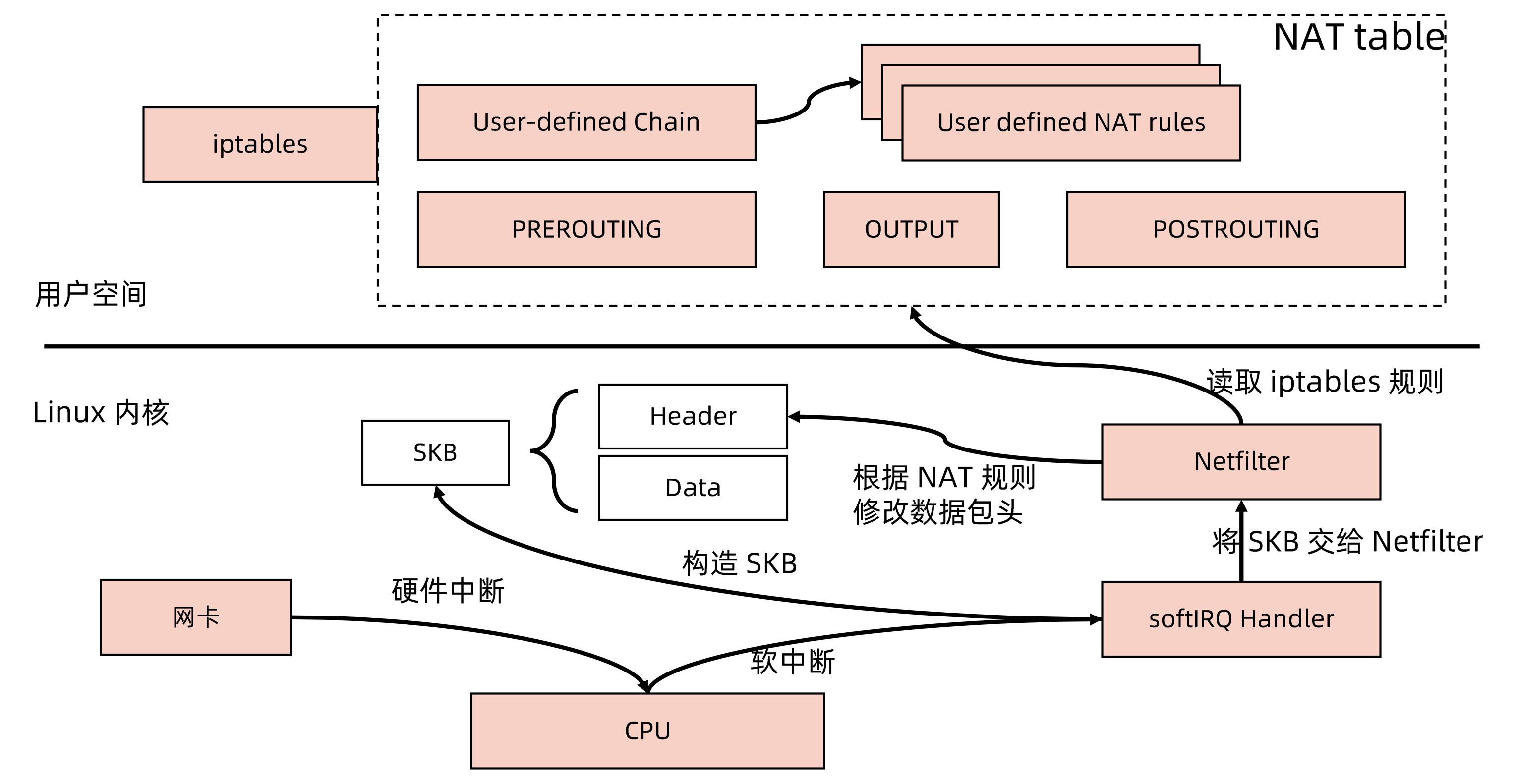
NAT
网络地址转换(Network AddressTranslation, NAT)通常通过修改数据包的源地址(Source NAT) 或目标地址(Destination NAT)来控制数据包的转发行为。
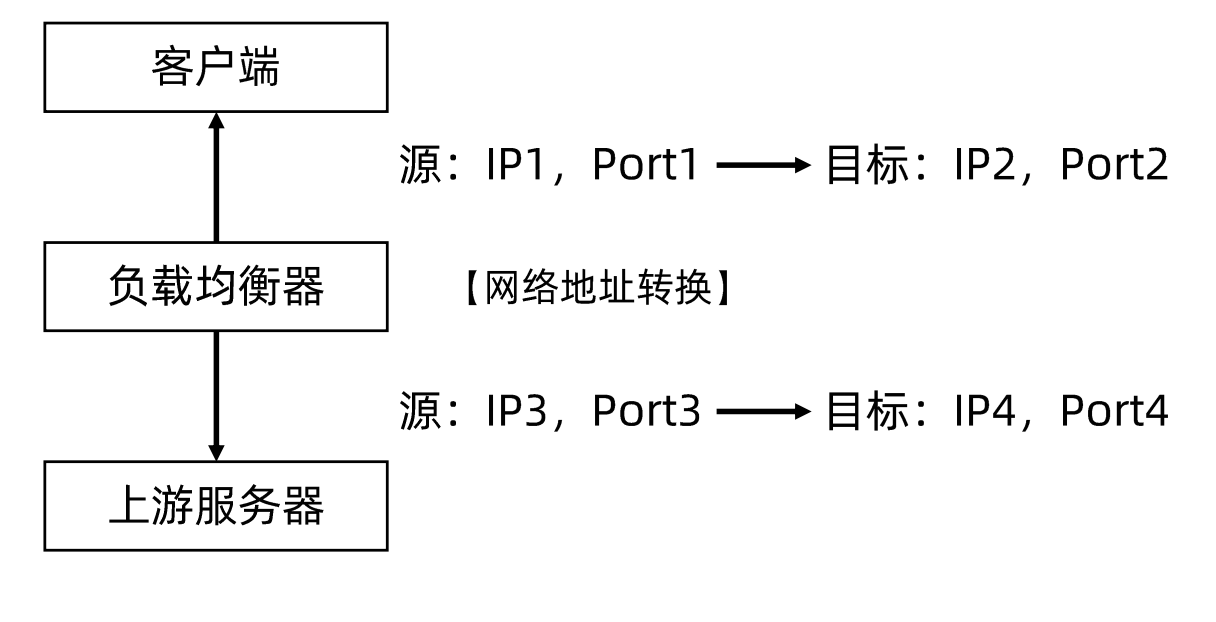
TCP/UDP Termination
为记录原始客户端IP地址,负载均衡功能不仅需要进行数据包的源目标地址修改,同时要记录原始客户端IP地址,基于简单的 NAT 无法满足此需求,于是行生出了基于传输层协议的负载均衡的另一种方案—TCP/UDP Termination 方案。
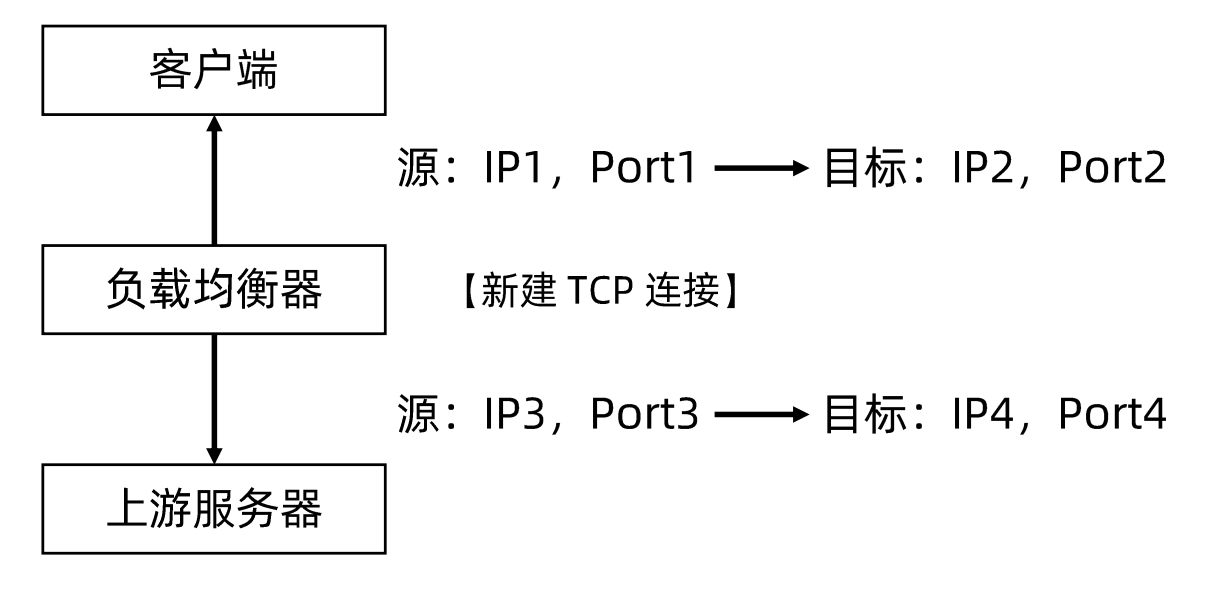
链路层负载均衡
- 在通信协议的数据链路层修改 MAC 地址进行负载均衡。
- 数据分发时,不修改IP 地址,指修改目标MAC 地址,,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
- 实际处理服务器 IP 和数据请求目的IP一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR 模式)
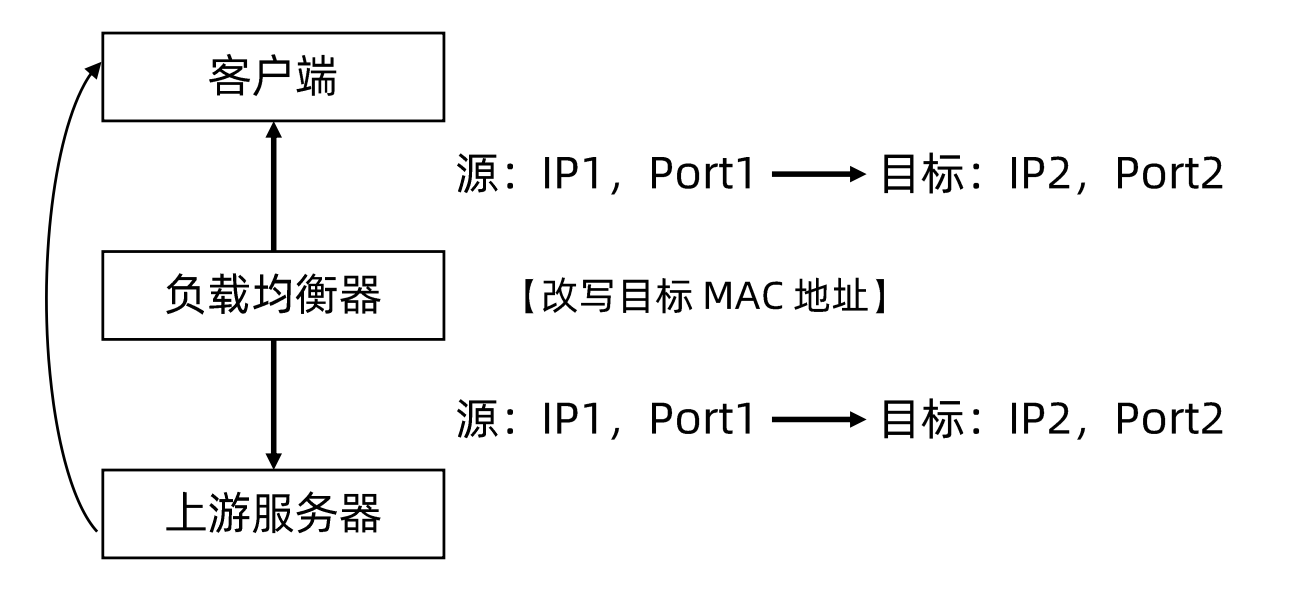
隧道技术
负载均衡中常用的隧道技术是IP over IP,其原理是保持原始数据包1P 头不变,在1P 头外层增加额外的IP包头后转发给上游服务器。
上游服务器接收IP数据包,解开外层IP包头后,剩下的是原始数据包。
同样的,原始数据包中的目标IP地址要配置在上游服务器中,上游服务器处理完数据请求以后,响应包通过网关直接返回给客户端。
Service
由两部分组成:
- service selector: kubernetes允许将pod对象通过label进行标记,并通过service selector定义基于pod标签的过滤规则,以便选择服务的上游应用实例
- ports: ports属性中定义了服务的端口,协议目标端口等信息
apiVersion: v1
kind: Service
metadata:
name: nginx-basic
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginxEndPoint
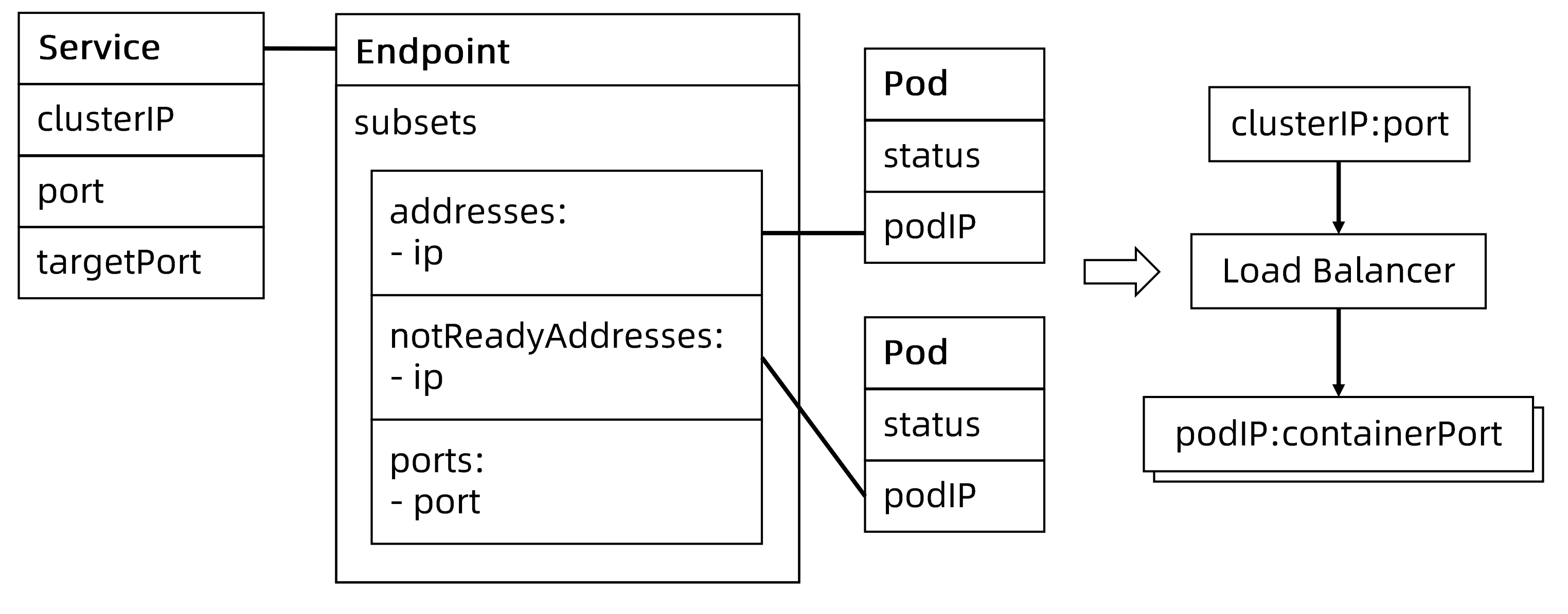
当Service的selector不为空时,Kubernetes Endpoint Controller 会侦听服务创建事件,创建与Service同名的 Endpoint 对象。
Selector能够选取的所有PodIP都会被配置到 addresses 属性中:
- 如果此时 selector所对应的filter查询不到对应的Pod,则addresses 列表为空。
- 默认配置下,如果此时对应的Pod为not ready状态,则对应的 PodIP 只会出现在 subsets 的notReadyAddresses属性中,这意味着对应的 Pod 还没准备好提供服务,不能作为流量转发的目标。
- 如果设置了 PublishNotReadyAdddress 为 true,则无论 Pod 是否就绪都会被加入 readyAddress list。
EndpointSlice
- 当某个Service对应的 backend Pod较多时,Endpoint对象就会因保存的地址信息过多而变得异常庞大。
- Pod状态的变更会引起 Endpoint 的变更,Endpoint的变更会被推送至所有节点,从而导致持续占用大量网络带宽。
- EndpointSlice对象,用于对Pod较多的Endpoint进行切片,切片大小可以自定义。
不定义selector的service
用户创建了Service但不定义Selector
- Endpoint Controller 不会为该 Service 自动创建 Endpoint。
- 用户可以手动创建 Endpoint 对象,并设置任意IP 地址到 Address 属性。
- 访问该服务的请求会被转发至目标地址。
通过该类型服务,可以为集群外的一组EndPoint创建服务。通常用来在集群内部访问集群外部的资源
Service、EndPoint和Pod的对应关系
Service的类型
- ClusterIp
- Service的默认类型,服务被发布至仅集群内部可见的虚拟IP 地址上。
- 在API Server启动时,需要通过
service-cluster-ip-range参数配置虚拟IP地址段,API Server中有用于分配IP地址和端口的组件,当该组件捕获Service对象并创建事件时,会从配置的虚拟IP地址段中取一个有效的IP地址,分配给该 Service 对象。
- nodePort
- 在API Server启动时,需要通过
node-port-range参数配置nodePort的范围(默认30000-32000),同样API Server组件会捕获Service对象并创建事件,即从配置好的nodePort范围取一个有效端口,分配给该Service - 每个节点的kube-proxy会尝试在服务分配的nodePort上建立侦听器接收请求,并转发给服务对应的后端Pod实例
- 在API Server启动时,需要通过
- LoadBalancer
- 企业数据中心一般会采购负载均衡器,作为外网请求进入数据中心内部的统一流量入口,针对不同的基础架构云平台,Kubernetes Cloud Manager提供支持不同供应商API的Service Controller。如果需要在Openstack云平台上搭建Kubernetes集群,那么只需提供一份openstack.rc, Openstack Service Controller即可通过调用LBaaS API完成负载均衡配置。
- Headless Service: Headless服务是用户将clusterIP显示定义为None的服务,意味着kubernetes不会为该服务分配统一入口,包括clusterIp,nodePort等,
- ExternalName Service: 为一个服务创建一个别名,
Service Topology
一个网络调用的延迟受客户端和服务器所处位置的影响,两者是否在同一节点、同一机架、同一可用区、同一数据中心,都会影响参与数据传输的设备数量。
在分布式系统中,为保证系统的高可用,往往需要控制应用的错误域(Failure Domain),比如通过反亲和性配置,将一个应用的多个副本部署在不同机架,甚至不同的数据中心。
Kubernetes提供通用标签来标记节点所处的物理位置,如:
topology.kubernetes.io/zone: us-west2-a
failure-domain.beta.kubernetes.io/region: us-west
failure-domain.tess.io/network-device: us-westo5-ra053
failure-domain.tess.io/rack: us_west02_02-314_19_12
kubernetes.io/hostname: node-1Service引入了topologyKeys属性,可通过如下设置来控制流量:
- 当topologykeys设置为
["kubernetes.io/hostname"]时,调用服务的客户端所在节点上如果有服务实例正在运行,则该实例处理请求,否则,调用失败。 - 当topologykeys设置为
["kubernetes.io/hostname", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]时,若同一节点有对应的服务实例,则请求会优先转发至该实例。否则,顺序查找当前zone及当前region是否有服务实例,并将请求按顺序转发。 - 当topologykeys设置为
["topology.kubernetes.io/zone", "-"]时,请求会被优先转发至当前zone的服务实例。如果当前zone不存在服务实例,则请求会被转发至任意服务实例。
做服务发现时,只访问本地的service,如果没有直接丢弃
apiVersion: v1
kind: Service
metadata:
name: nodelocal
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
topologyKeys:
- kubernetes.io/hostname做服务发现时,优先访问本地节点的service,
apiVersion: v1
kind: Service
metadata:
name: prefer-nodelocal
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
topologyKeys:
- kubernetes.io/hostname
- topology.kubernetes.io/zone
- topology.kubernetes.io/region
- '-'kube-proxy
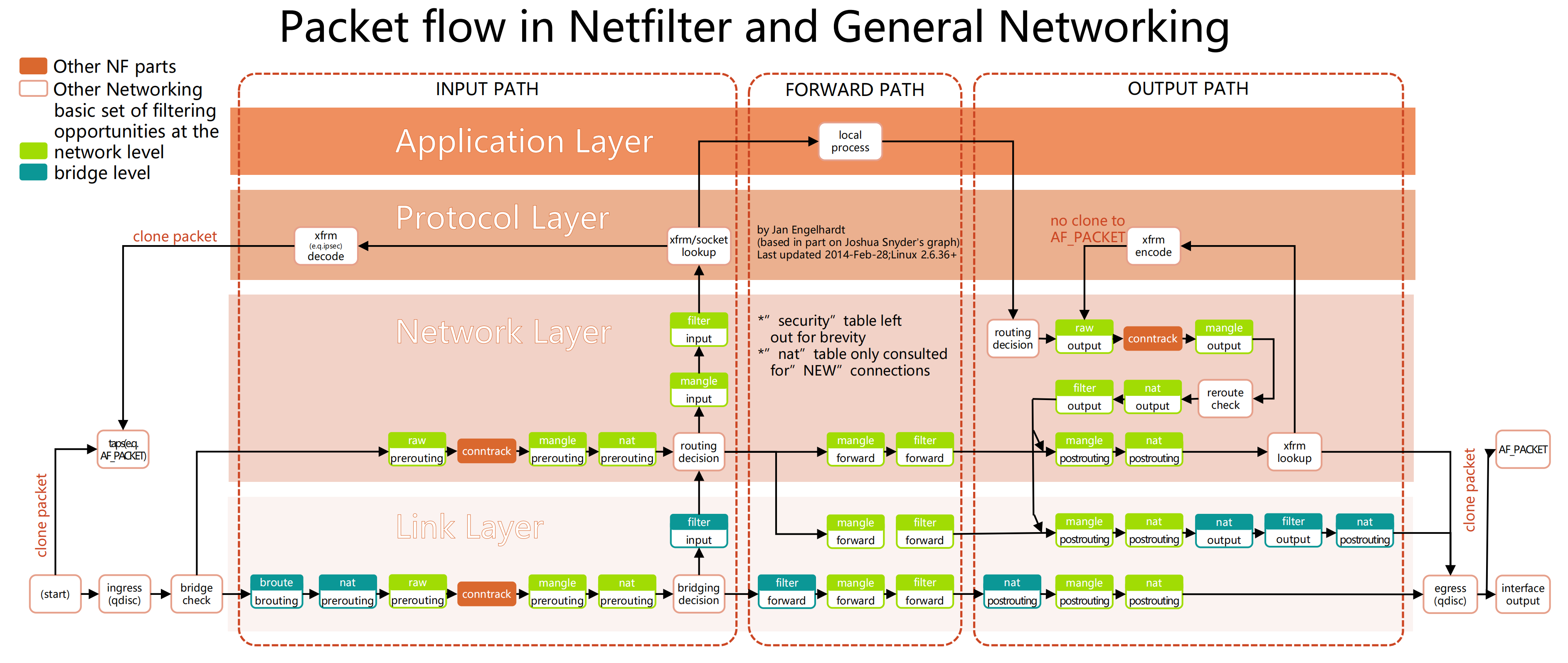
每台机器上都运行一个kube-proxy服务,它监听API Server中service和endpoint的变化情况,并通过iptables等来为服务配置负载均衡(仅支持TCP和UDP)
kube-proxy可以直接运行在物理机上,也可以已static pod或者DaemonSet的方式运行
支持以下几种实现:
- : 最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过iptables转发到这个端口,然后在其内部负载均衡到实际的 Pod。该方式最主要的问题是效率低,有明显的性能瓶颈。
- : 目前推荐的方案,完全以iptables规则的方式来实现service负载均衡。该方式最主要的问题是在服务多的时候产生太多的 iptables 规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题。
- : 为解决 iptables 模式的性能问题,v1.8新增了ipvs模式,采用增量式更新,并可以保证service更新期间连接保持不断开。
- : 同 userspace,但仅工作在 windows 上。
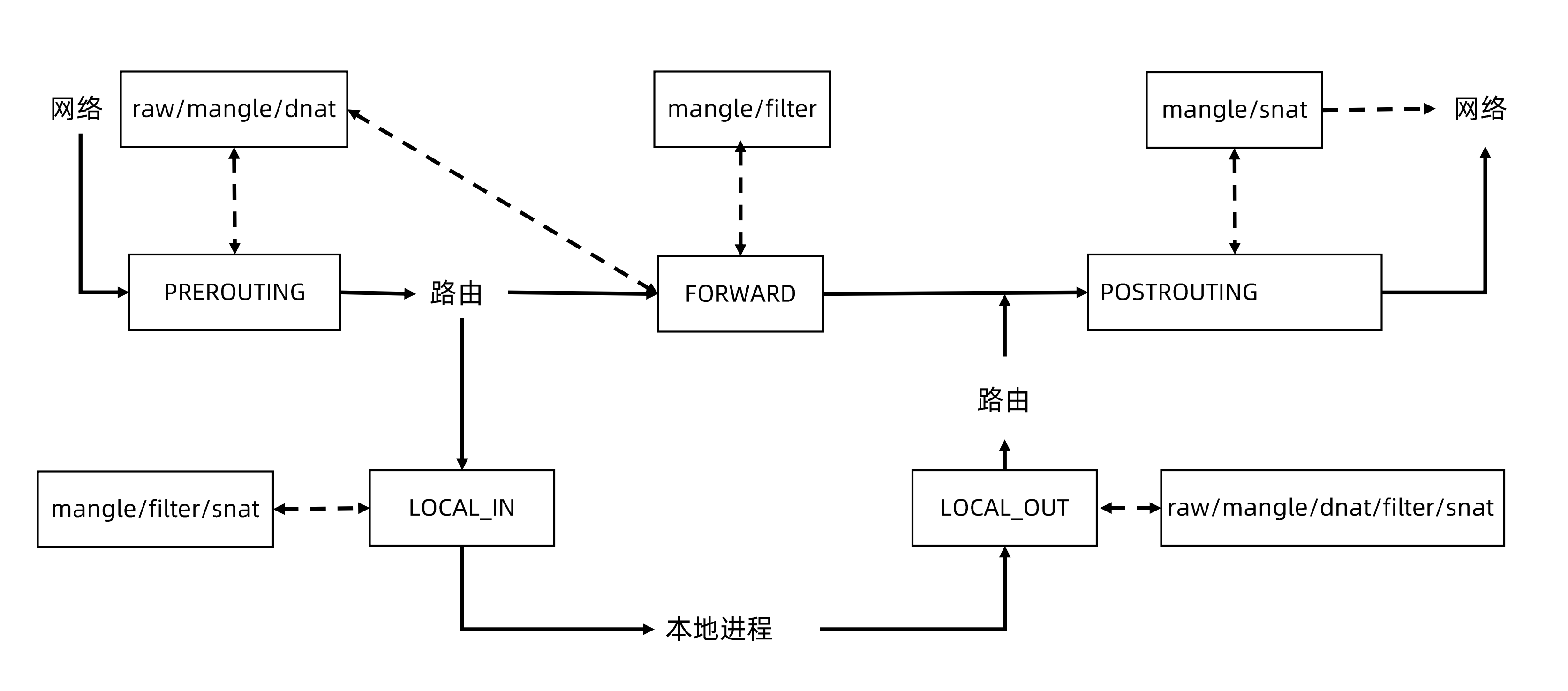
iptables支持的hook点
| tables/chain | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| raw | 支持 | 支持 | |||
| mangle | 支持 | 支持 | 支持 | 支持 | 支持 |
| dnat | 支持 | 支持 | |||
| filter | 支持 | 支持 | 支持 | ||
| snat | 支持 | 支持 | 支持 |
kube_proxy工作原理
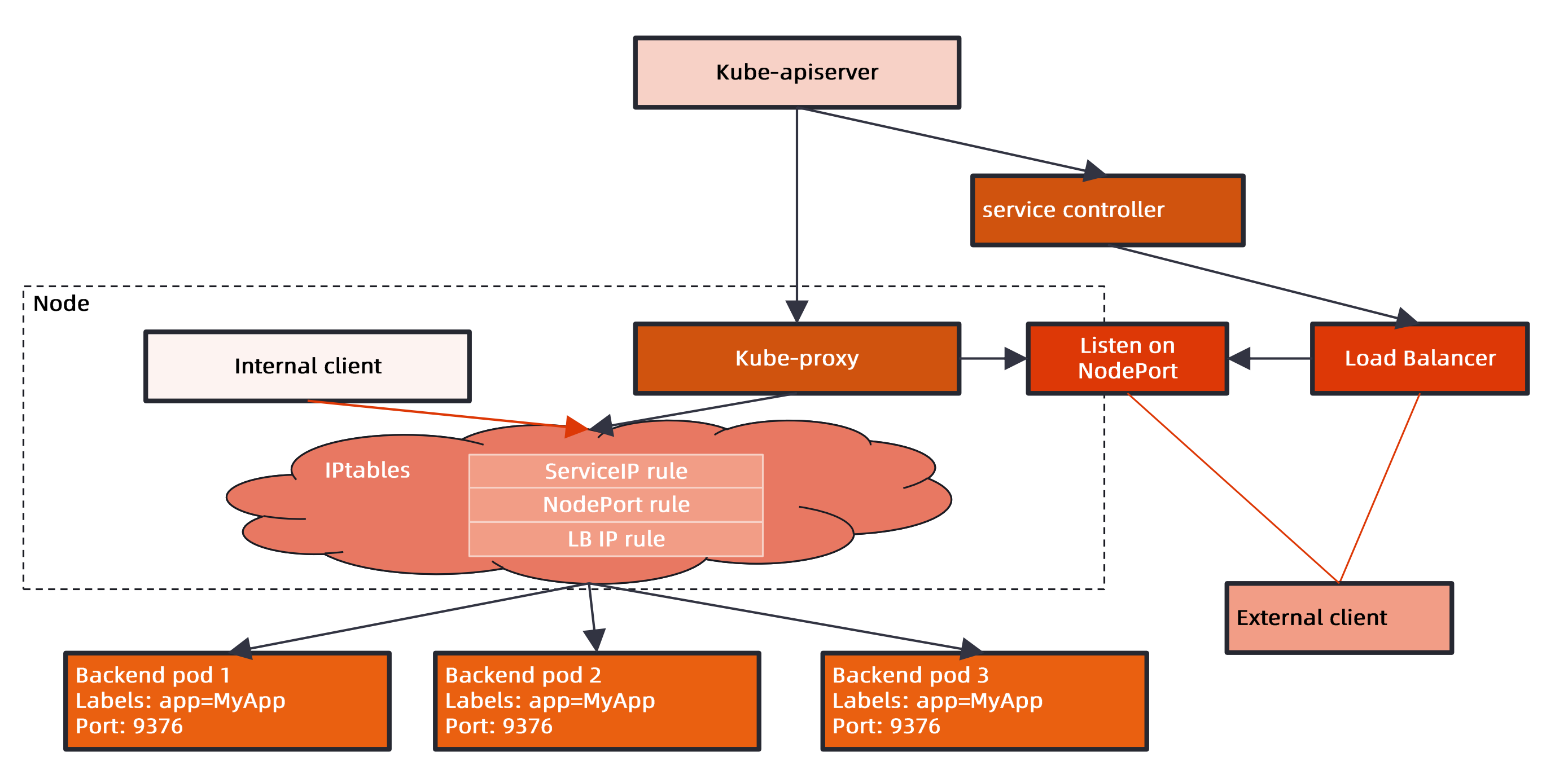
iptables模式
Tip
⌘ 可通过iptables-save -t table名查看所有添加的命令
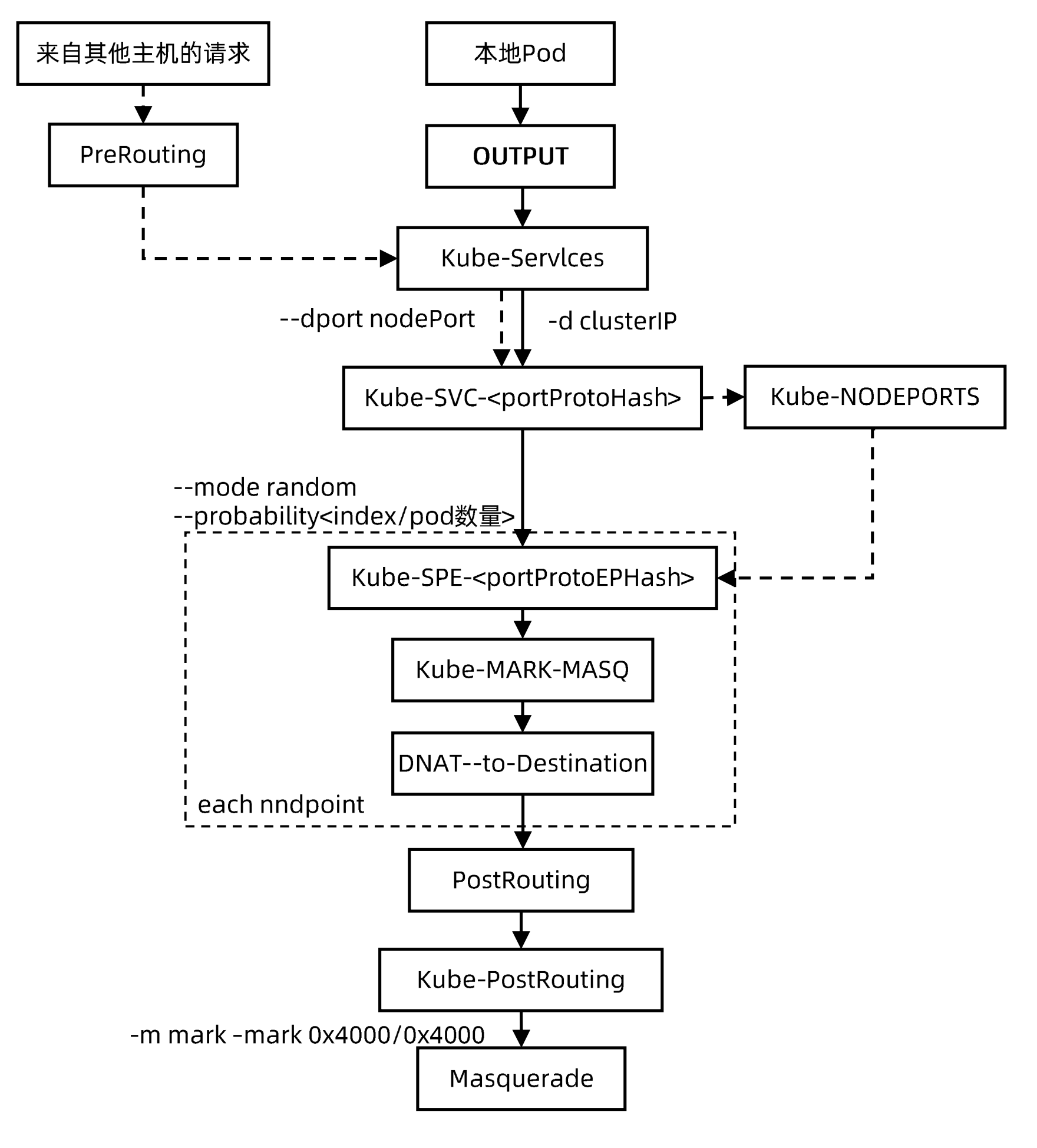
kube-proxy添加的iptables dnat规则,PREROUTING和OUTPUT统一由KUBE-SERVICES链接管路由
# pod
192.168.166.165、192.168.166.164、192.168.166.17
# service
nginx-basic ClusterIp 10.105.164.239 <none> 80/TCP 25m app=nginx
# KUBE-SERVICES路由接管
:KUBE-SERVICES - [0:0]
-A PREROUTING -m comment --comment "kubernets service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes services portals" -j KUBE-SERVICES
# dnat规则
-A KUBE-SERVICES -d 10.105.164.239/32 -p tcp -m comment --comment "default/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-SVC-WWRFY3PZTW3FGMOW
# 33.3%的概率去192.168.166.164:80
-A KUBE-SVC-WWRFY3PZ7W3FGMOW -m comment ——comment "default/nginx-basic:http" -m statistic -mode random --probability 0.33333333349 -j KUBE-SEP-COQT7DYNIZXRZLTL
-A KUBE-SEP-COQT7DYNIZXRZLTL -P tcp -m comment --comment "default/nginx-basic:http" -m tcp -j DNAT --to-destination 192.168.166.164:80
# 50%的概率去192.168.166.165:80
-A KUBE-SVC-WWRFY3PZTW3FGMOW -m conment —conment "default/nginx-basic:htlp"-m statistic —mode randon --probability 0.50000000000 -j KUBE-SEP-GY5VVSRZZSAGTZHE
-A KUBE-SEP-GY5VVSRZZSAGTZHE -p tcp -m comment --comment “default/nginx-basic:http" -m tcp -j DNAT --to-destination 192.168.166.165:80
# 100%的概率去192.168.166.167:80
-A KUBE-SVC-WWRFY3PZTW3FGMOW -m comment --comment "default/nginx-basic:http" -j KUBE-SEP-VAZ5IXJHC5UG4ISY
-A KUBE-SEP-VAZ5IXJHC5UG4ISY -p tcp -m comment -comment "default/nginx-basic:http" -m tcp -j DNAT --to-destination 192.168.166.167:80ipvs模式
iptables模式存在的问题
- iptables规则过于复杂,任何一个负载均衡的配置都需要很多规则去堆叠
- 负载均衡的策略过于粗旷
- 规则刷新效率低(kube-proxy每次更新,清除iptables重新刷规则)
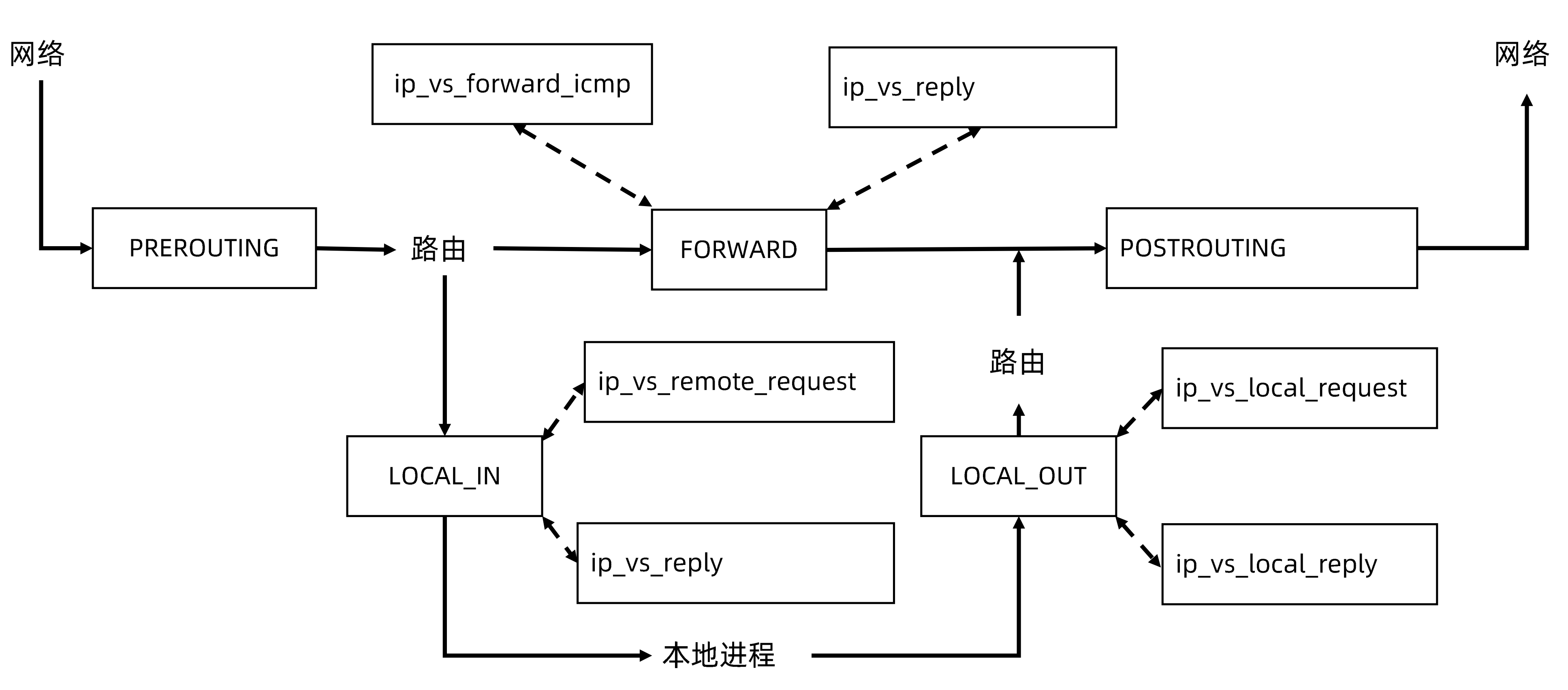
ipvs和iptables模式上最大的差别
- ipvs没有
PREROUTINGhook点,iptables模式下,在访问ClusterIP,在做路由判决前,已经将路由包的信息给替换 - ipvs模式需要将所有的service ClusterIP绑在当前节点的一个设备上,防止路由判决时丢弃路由包
模式切换: iptables -> ipvs
kubectl edit configmap kube-proxy -n kube-system
set mode: "ipvs"DNS
CoreDNS 包含一个内存态 DNS,以及与其他controller类似的控制器。
CoreDNS 的实现原理是,控制器监听Service和Endpoint的变化并配置DNS,客户端Pod在进行域名解析时,从CoreDNS中查询服务对应的地址记录。
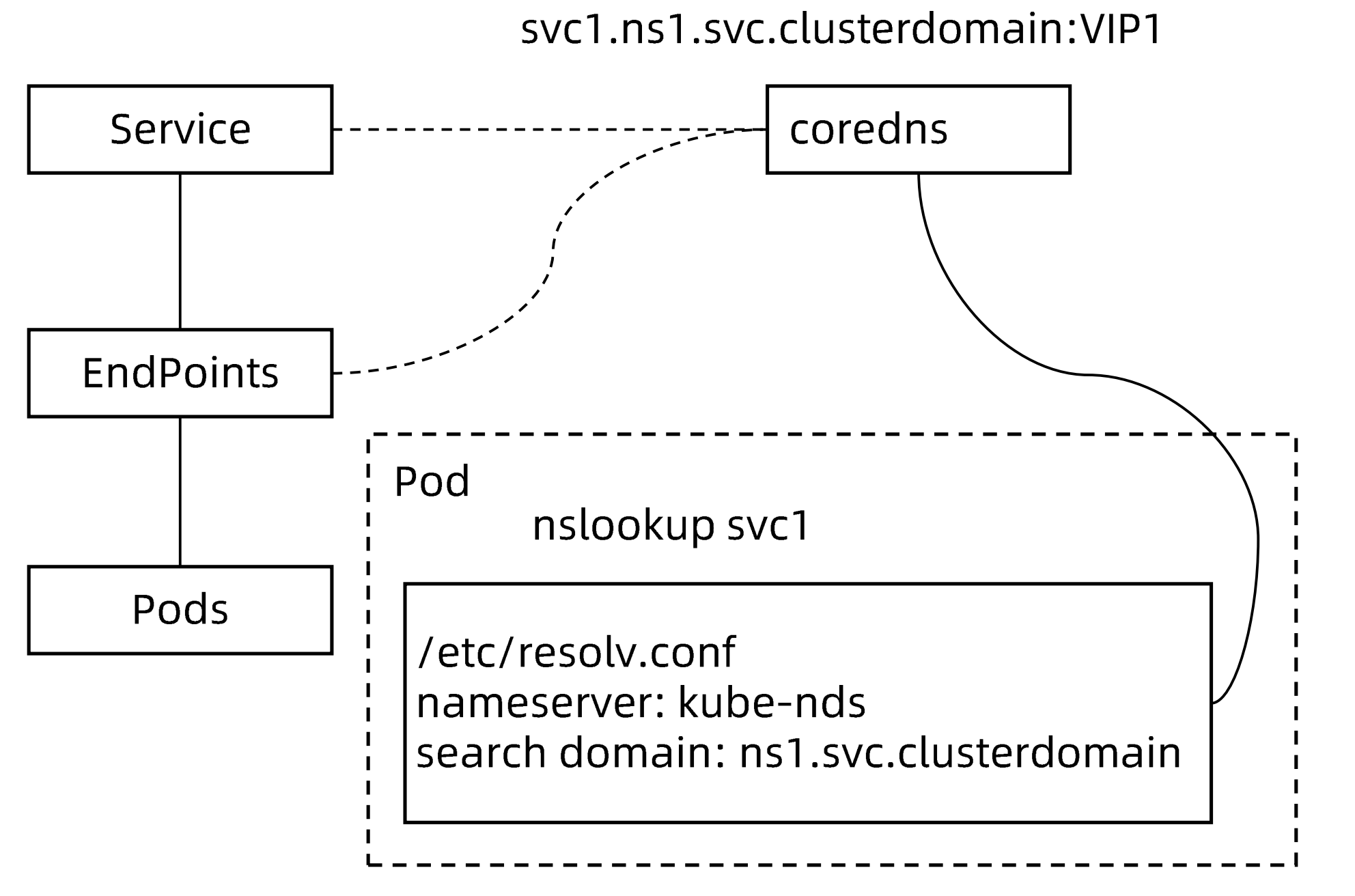
不同类型服务的DNS记录
ClusterIP、 nodePort、 LoadBalancer类型的Service都拥有API Server分配的clusterIP,
CoreDNS会为这些Service创建FQDN格式为
$svcname.$namespace.svc. $clusterdomain:clusterIP的A记录及PTR记录,并为端口创建SRV记录。顾名思义,无头,是用户在Spec显式指定ClusterIP为None的Service,对于这类Service, APIServer不会为其分配ClusterIP。CoreDNS为此类 Service创建多条A记录,并且目标为每个就绪的PodIP。
另外,每个Pod会拥有一个 FQDN格式为
$podname.$svcname.$namespace.svc.$clusterdomain的A记录指向PodIP。此类 Service用来引用一个已经存在的域名,CoreDNS会为该Service创建一个cname记录指向目标域名。
pod内部的/etc/resolve.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.10
options ndots:4其中ndots代表如果是4个点以下则判定为短域名,会自动在域名后按照search的顺序添加域名后缀进行dns解析
Caution
当pod启动时,同一个namespace的所有service都会以环境变量的形式设置到容器内,通过enableServiceLinks参数进行控制,如果为true则代表设置环境变量
当一个namespace内service过多,可能会导致pod无法创建,是因为启动命令中包含env信息,过长导致命令被截断,只需将enableServiceLinks设置为false即可
Pod的dns策略
- Default: Pod从运行所在的节点继承名称解析配置
- ClusterFirst: 与配置的集群域后缀不匹配的任何DNS查询(例如 "www.kubernetes.io")都会由DNS服务器转发到上游名称服务器。集群管理员可能配置了额外的存根域和上游DNS服务器。
- ClusterFirstWithHostNet: 对于以hostNetwork方式运行的Pod,应将其DNS策略显式设置为ClusterFirstWithHostNet。否则,以hostNetwork方式和ClusterFirst策略运行的Pod将会做出回退至 "Default" 策略的行为。
- None: 此设置允许 Pod 忽略 Kubernetes 环境中的 DNS 设置。Pod 会使用其 dnsConfig 字段所提供的 DNS 设置。
Note
说明:
Default不是默认的 DNS 策略。如果未明确指定dnsPolicy,则使用ClusterFirst。
自定义DNSPolicy
当存在自己的nameserver,或者自己的searchDomain
spec:
dnsPolicy: None
dnsConfig:
nameservers:
- 1.2.3.4
searchs:
- xx.ns1.svc.cluster.local
- xx.daemon.com
options:
- name: ndots
value: '2'Ingress
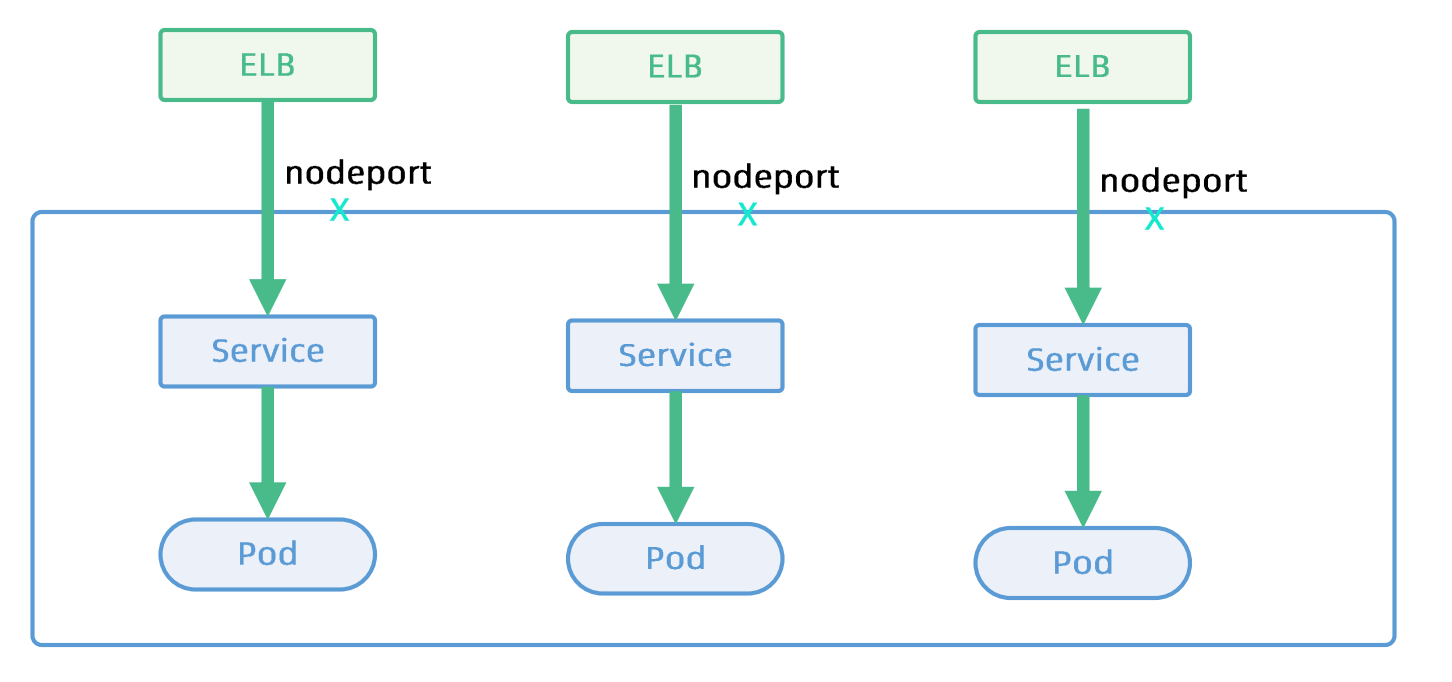
Service是基于L4的服务
- 基于iptables/ipv4的分布式四层负载均衡技术
- 多种Load Balancer Provider 提供与企业现有的ELB的整合
- kube-proxy基于 iptables rules为 k8s形成全局统一的distibuted load balancer.
- kube-porxy是一种mesh,Internal Client无论通过podIp,nodePort还是LB VIP都经由kube-proxy跳转至Pod
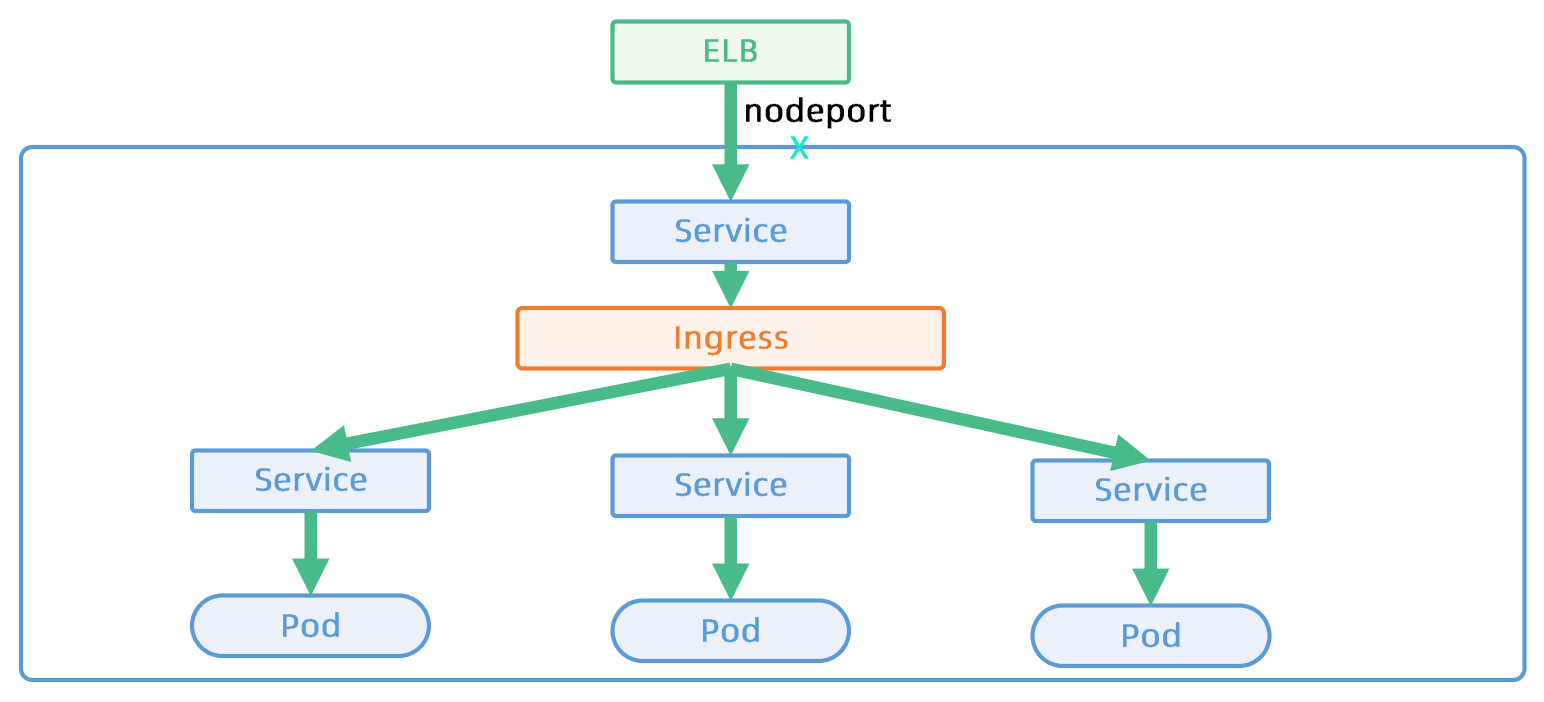
Ingress是基于L7的服务
- TLS termination
- L7 path forwarding
- URL/http header rewrite
ingress-nginx
- Install ingress controller
templates: nginx-ingress-deployment.yaml
kubectl create -f nginx-ingress-deployment.yamlmore templates: ingress-nginx templates
- Generate key-cert
# use openssl (version >= 1.1.1f) on Linux, e.g. Ubuntu 20.04
# don't run on macOS, which is using LibreSSL
# instead, you can `brew install openssl` on macOS
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=cncamp.com/O=cncamp" -addext "subjectAltName = DNS:cncamp.com"- Create secret
kubectl create secret tls cncamp-tls --cert=./tls.crt --key=./tls.key- Create a ingress
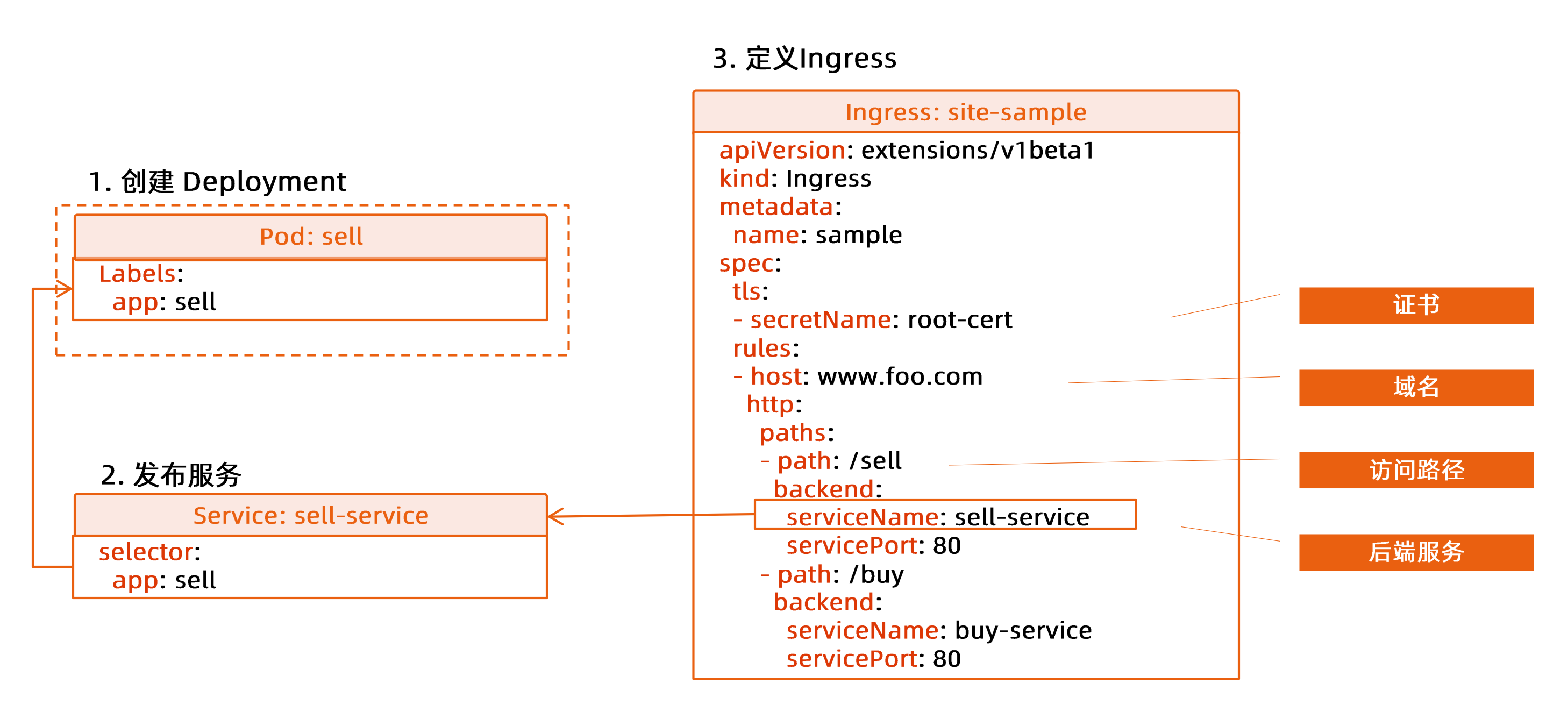
ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gateway
annotations:
kubernetes.io/ingress.class: nginx
spec:
tls:
- hosts:
- cncamp.com
secretName: cncamp-tls
rules:
- host: cncamp.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx
port:
number: 80- Test the result
curl -H "Host: cncamp.com" https://10.109.204.181 -v -k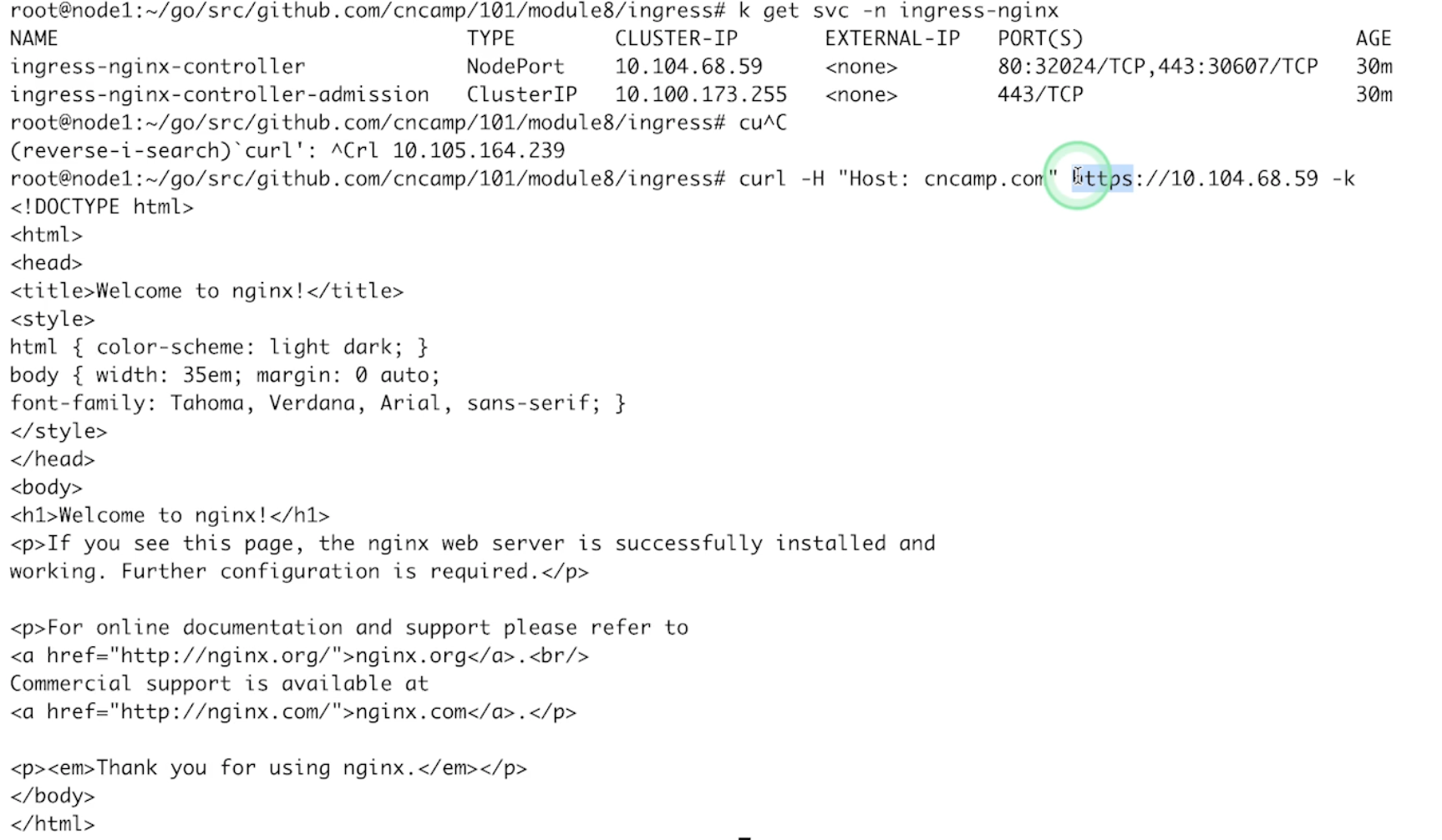
ingress存在的问题
- 针对流量管理的需求负载,而ingress支持的spec过于简单,导致需求无法满足
- 依赖于各个社区的provider的实现,provider之间无法统一,导致不同ingress controller的实现不一样
