TW状态增多,会导致端口占用严重,新建连接时由于端口不足,会遍历hash表中的已用端口使用情况,尝试复用现有端口。这样就导致内核在查找端口时耗用时间太多,进而CPU升高
建议阈值: 网络环境好的情况下, tcp_tw_timeout=10 效果比较明显 —> tcp_tw_timeout == MSL
常用命令
统计time_wait临时端口分布
ss -natup|grep TIME-WAIT|sort|awk '{print $6}'|awk -F ':' '{print $2}'|sort|uniq -c
# output
TW个数 目的port
-------------------
5452 1367
5059 21617
2173 22000
2773 8100
102 8300
11296 9007
306 9101统计链接状态分布情况
ss -natlp|awk '/^tcp/ {++state[$2]} END {for(key in state) print key,"t",state[key]}'
第一次实验
试验的机器:9.134.32.173
[前置条件]:
net.ipv4.tcp_max_tw_buckets = 524288
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_timeout = 60
# 设置临时端口为1个
sysctl -w "net.ipv4.ip_local_port_range=32768 32768"
[root@VM_32_173_centos ~]# ss -nat|grep TIME-WAIT
TIME-WAIT 0 0 127.0.0.1:32768 127.0.0.1:9007 ----> 9007端口可以telnet通
TIME-WAIT 0 0 9.134.32.173:32768 9.134.117.29:42203 ----> 42203端口可以telnet通
TIME-WAIT 0 0 9.134.32.173:32768 9.134.124.69:42203 ----> 42203端口可以telnet通
TIME-WAIT 0 0 9.134.32.173:32768 9.134.65.103:42203 ----> 42203端口可以telnet通
[root@VM_32_173_centos ~]# ss -nat|grep ESTAB
ESTAB 0 0 [::ffff:9.134.32.173]:32768 [::ffff:9.135.68.154]:3306
# 当前只有一个TCP临时端口, 所以telnet 42203的时候, 命中同一个四元组, 所以可以复用该链接(tw_reuse)
[root@VM_32_173_centos ~] telnet 9.134.117.29 42203
Trying 9.134.117.29...
Connected to 9.134.117.29.
Escape character is '^]'.
^C^C^CConnection closed by foreign host.
# 当前只有一个TCP临时端口, 且该四元组已经被ESTAB链接占用, 且不能分配新的临时端口。 ---> 当转为TIME_WAIT状态后, 可以利用tw_reuse, 重新建立链接
[root@VM_32_173_centos ~]# telnet 9.135.68.154 3306
Trying 9.135.68.154...
telnet: connect to address 9.135.68.154: Cannot assign requested address
# 关闭tw_reuse后 --> 不能复用TIME_WAIT链接
net.ipv4.tcp_tw_reuse = 0
[root@VM_32_173_centos ~]# telnet 9.134.117.29 42203
Trying 9.135.68.154...
telnet: connect to address 9.135.68.154: Cannot assign requested address
=============> 注意: 跨机器bind(), 也会报同样的错误message [例如: 机器A的进程, 监听机器B的IP地址]
不同目的ip+port, 代表多个不同的TCP链接
[root@VM_32_173_centos ~]# ss -nat|grep TIME-WAIT
TIME-WAIT 0 0 127.0.0.1:32768 127.0.0.1:9007
TIME-WAIT 0 0 9.134.32.173:32768 9.134.117.29:42203
TIME-WAIT 0 0 9.134.32.173:32768 9.134.124.69:42203
TIME-WAIT 0 0 9.134.32.173:32768 9.134.65.103:42203
TIME-WAIT 0 0 [::ffff:9.134.32.173]:32768 [::ffff:9.135.38.73]:80试验结论
Q: ip_local_port_range是否会影响其它机器过来的链接?
不会影响, 临时端口: 58632是在机器B分配的, 和当前机器无关
# 登录另外的机器B
telnet 9.134.32.173 8083
# 然后在173查看链接情况:
ss -nat|grep 95
ESTAB 0 0 [::ffff:9.134.32.173]:8083 [::ffff:9.134.242.95]:58632net.ipv4.tcp_tw_timeout 可以调整TCP状态中TIME_WAIT的过期时间,默认是60s == 2MSL(一个MSL == 30s)
- 调大ip_local_port_range范围上限
- 缩短tcp_tw_timeout时间, 加速tcp链接回收, 回收的端口可以重新用来分配 — 短连接较多的场景调整该参数效果比较明显
local_port_range范围要大于max_tw_buckets的数量
只要 port 范围 - tcp_max_tw_bucket 大于一定的值,那么就始终有 port 端口可用,这样就可以避免再次到调大临界值得时候继续击穿临界点。
cat /proc/sys/net/ipv4/ip_local_port_range
22768 61000
cat /proc/sys/net/ipv4/tcp_max_tw_buckets
20000第二次实验
试验的机器:9.134.32.173
[前置条件]:
net.ipv4.ip_local_port_range = 32768 32768
net.ipv4.tcp_max_tw_buckets = 524288
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_timeout = 60
Every 2.0s: watch 'ss -natp|grep -E "32768|32769"'
ESTAB 0 0 9.134.32.173:32768 9.84.230.195:9988 users:(("secu-tcs-agent",pid=20896,fd=9))
TIME-WAIT 0 0 9.134.32.173:32769 9.134.65.69:24008
ESTAB 0 0 9.134.32.173:32768 9.134.65.69:24008 users:(("cc_agent",pid=6800,fd=4))
ESTAB 0 0 [::ffff:9.134.32.173]:32768 [::ffff:9.134.6.167]:8762 users:(("java",pid=9018,fd=428)) -----------> test
TIME-WAIT 0 0 [::ffff:9.134.32.173]:32768 [::ffff:9.135.38.140]:80
TIME-WAIT 0 0 [::ffff:9.134.32.173]:32769 [::ffff:9.135.38.140]:80
# 因为临时端口只开了32768, 且当前存在一个ESTAB的四元组. 所以重新telnet的时候, 出现报错. 如果当前链接是TIME_WAIT状态, 则telnet可以正常建立链接
[root@VM_32_173_centos /proc/6786]# telnet 9.134.6.167 8762
Trying 9.134.6.167...
telnet: connect to address 9.134.6.167: Cannot assign requested address
# 怎样规避"Cannot assign requested address"
调整临时端口范围:
net.ipv4.ip_local_port_range = 32768 32769
[root@VM_32_173_centos /proc/6786]# telnet 9.134.6.167 8762
Trying 9.134.6.167...
Connected to 9.134.6.167.
Escape character is '^]'.
然后ss -natp会新增一条32769的ESTAB链接:
ESTAB 0 0 9.134.32.173:32769 9.134.6.167:8762 users:(("telnet",pid=23630,fd=3))只有相同临时端口+访问固定的ip+端口, 相同的协议。。 如果下一个时刻,非常多的请求过来了,发现已经存在这个5元组了, 就利用tw_use这个属性来确认是不是要复用
[root@VM_32_173_centos ~]# ss -nat|grep TIME-WAIT
TIME-WAIT 0 0 127.0.0.1:32768 127.0.0.1:9007
TIME-WAIT 0 0 9.134.32.173:32768 9.134.117.29:42203
TIME-WAIT 0 0 9.134.32.173:32768 9.134.124.69:42203
TIME-WAIT 0 0 9.134.32.173:32768 9.134.65.103:42203
1、这个是不同的链接,根本不是链接复用
2、五元组任意一个值不相同,那就是一条新的链接
3、即使临时端口相同,这个只是一个数字,没有任何含义,最终其实只是共用网卡了,不存在都是走32768这个端口出去的问题
4、也就是上面这个TIME_WAIT的列表,4个链接还没用到tw_reuse这个属性。
[root@VM_32_173_centos ~]# ss -nat|grep TIME-WAIT
TIME-WAIT 0 0 127.0.0.1:32768 127.0.0.1:9007
TIME-WAIT 0 0 9.134.32.173:32768 9.134.117.29:42203
TIME-WAIT 0 0 9.134.32.173:32768 9.134.124.69:42203
TIME-WAIT 0 0 9.134.32.173:32768 9.134.65.103:42203
——————>
TIME-WAIT 0 0 9.134.32.173:32768 9.134.65.103:42203
还新增一条,就会用到reuse这个参数了 (因为五元组完全一致)tlinux找临时端口的规则 每个端口每个连接要检查,一直重试下去,所以很耗CPU,例如:
ESTAB Client A (32769) -> Server B(8080)
ESTAB Client C (32769) -> Server B(8081)
ESTAB Client D (32769) -> Server B(8088)
ESTAB Client E (32770) -> Server B(8080)
ESTAB Client F (32770) -> Server B(8081)
ESTAB Client G (32770) -> Server B(8088)当Client -> Server B(8081)进来的时候, 先看一下32769上的链接情况, 如果没有相同四元组的链接, 则直接使用。但是发现"ESTAB Client C (32769) -> Server B(8081)"已经匹配了, 所以会放弃此端口, 开始遍历32770上的所有连接, 以此类推, 直到找到可以用的。
结论
- 每个端口有个连接表,要检查连接表里的连接,知道确认不可用。然后下一个。CPU开销取决于平均要检查多少此才能找到一个可用。
- 至于循环顺序,最新的内核是connect优先找偶数端口。偶数耗尽时再找奇数端口。主要时为了避免bind 端口0问题,因为bind 端口0分配端口不能reuse。这样偶数耗尽时CPU开销会很大。 --> 是32768, 32770, 32772 … 这样; 然后找一轮找不到, 就会从32769, 32771, 32773遍历。
time_wait状态产生的原因
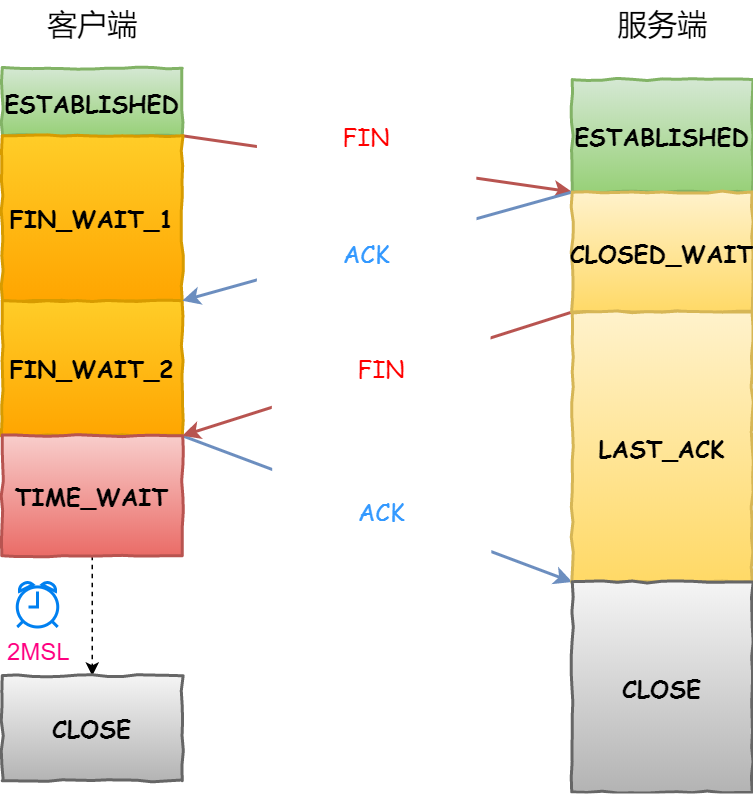
- 为实现TCP全双工连接的可靠释放
由TCP状态变迁图可知,假设发起主动关闭的一方(client)最后发送的ACK在网络中丢失,由于TCP协议的重传机制,执行被动关闭的一方(server)将会重发其FIN, 在该FIN到达client之前,client必须维护这条连接状态,也就说这条TCP连接所对应的资源(client方的local_ip,local_port)不能被立即释放或重新分配, 直到另一方重发的FIN达到之后,client重发ACK后,经过2MSL时间周期没有再收到另一方的FIN之后,该TCP连接才能恢复初始的CLOSED状态。 如果主动关闭一方不维护这样一个TIME_WAIT状态,那么当被动关闭一方重发的FIN到达时,主动关闭一方的TCP传输层会用RST包响应对方,这会被对方认为是有错误发生,然而这事实上只是正常的关闭连接过程,并非异常。
确保被动关闭方收到ACK,连接正常关闭,且不因被动关闭方重传FIN影响下一个新连接
- 为使旧的数据包在网络因过期而消失 — 防止数据错乱 为说明这个问题,我们先假设TCP协议中不存在TIME_WAIT状态的限制,再假设当前有一条TCP连接:(local_ip, local_port, remote_ip,remote_port),因某些原因, 我们先关闭,接着很快以相同的四元组建立一条新连接。本文前面介绍过,TCP连接由四元组唯一标识,因此,在我们假设的情况中,TCP协议栈是无法区分前后两条TCP连接的不同的, 在它看来,这根本就是同一条连接,中间先释放再建立的过程对其来说是“感知”不到的。这样就可能发生这样的情况:前一条TCP连接由local peer发送的数据到达remote peer后, 会被该remot peer的TCP传输层当做当前TCP连接的正常数据接收并向上传递至应用层(而事实上,在我们假设的场景下,这些旧数据到达remote peer前, 旧连接已断开且一条由相同四元组构成的新TCP连接已建立,因此,这些旧数据是不应该被向上传递至应用层的),从而引起数据错乱进而导致各种无法预知的诡异现象。 作为一种可靠的传输协议,TCP必须在协议层面考虑并避免这种情况的发生,这正是TIME_WAIT状态存在的第2个原因。
2MSL:报文最大生存时间,确保旧的数据不会影响新连接
总结
具体而言,local peer主动调用close后,此时的TCP连接进入TIME_WAIT状态,处于该状态下的TCP连接不能立即以同样的四元组建立新连接, 即发起active close的那方占用的local port在TIME_WAIT期间不能再被重新分配。由于TIME_WAIT状态持续时间为2MSL,这样保证了旧TCP连接双工链路中的旧数据包均因过期(超过MSL)而消失,此后,就可以用相同的四元组建立一条新连接而不会发生前后两次连接数据错乱的情况。
调优心得
Linux 提供了tcp_max_tw_buckets参数,当 TIME_WAIT 的连接数量超过该参数时,新关闭的连接就不再经历 TIME_WAIT 而直接关闭. 当服务器的并发连接增多时,相应地,同时处于 TIME_WAIT 状态的连接数量也会变多,此时就应当调大tcp_max_tw_buckets参数,减少不同连接间数据错乱的概率。当然tcp_max_tw_buckets 也不是越大越好,毕竟内存和端口都是有限的。
