kube-scheduler
负责分配调度Pod到集群内的节点上,它监听kube-apiserver,查询还未分配Node的Pod,然后根据调度策略为这些Pod分配节点(更新Pod的NodeName字段)
调度器需要充分考虑诸多的因素
- 公平调度
- 资源高效利用
- Qos
- affinity和anti-affinity
- 数据本地化(data locality)
- 内部负载干扰(inter-workload)
- deadlines
kube-scheduler 调度分为两个阶段
- predicate: 过滤不符合条件的节点
- priority: 优先级排序, 选择优先级最高的节点
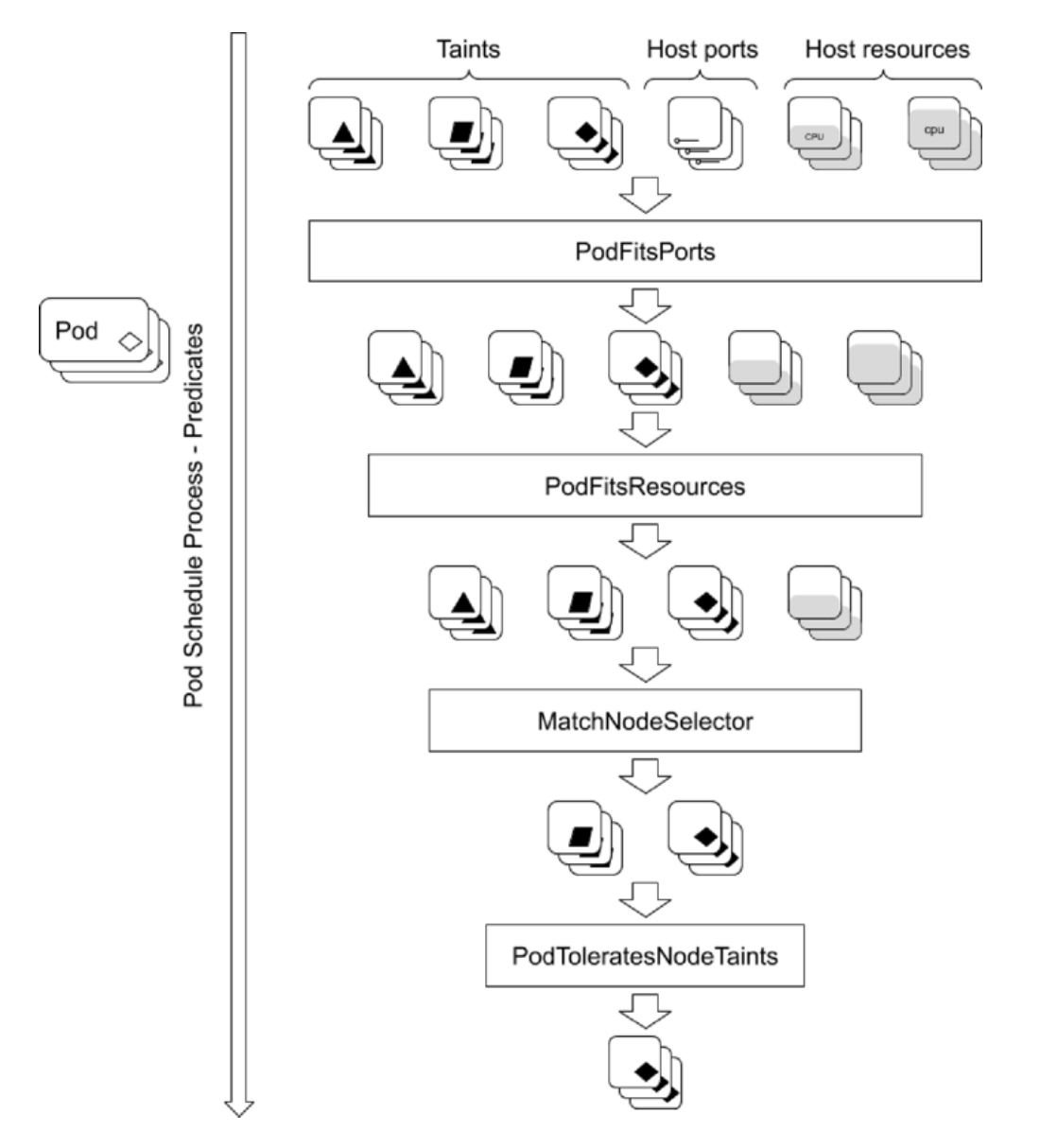
Predicates
策略(列举了部分):
- PodFitsHostPorts: 检查是否有Host Ports冲突
- PodFitsPorts: 同PodFitsHostPorts
- PodFitsResources: 检查Node的资源是否充足,包括允许的Pod数量、CPU、内存、GPU个数以及其他的
- HostName: 检查
pod.Spec.NodeName是否与候选节点一致 - MatchNodeSelector: 检查候选节点的
Pod.Spec.NodeSelector是否匹配 - NoVolumeZoneConflict: 检查volume zone是否冲突
Priorites
通过策略给节点打分,汇总后将得分最高的节点排在前面
策略(列举了部分):
- SelectorSpreadPriority: 优先减少节点上属于同一个Service活Replication Controller的Pod数量
- InterPodAffinityPriority: 优先将Pod调度到相同的拓扑上去(如同一个节点、Rack、Zone 等)
- LeastRequestedPriority: 优先调度到请求资源少的节点上去
- BalancedResourceAllocation: 优先平衡各节点的资源使用
- NodeAffinityPriority: 优先调度到匹配 NodeAffinity 的节点上
- TaintTolerationPriority: 优先调度到匹配 TaintToleration 的节点上
资源需求
nginx-with-resource.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: 1Gi
cpu: 1
requests:
memory: 256Mi
cpu: 100m- requests: 给调度器使用,表示最少需要的资源。
- limits: 给Cgroup使用,表示最多使用的资源
- CPU:
- requests: kubernetes调度pod时,会判断当前节点正在运行的Pod的CPU Request的总和,再加上当前调度Pod的CPU Request,计算是否超过节点的CPU的可分配资源。
- limits: 配置cgroup以限制资源上限
- 内存:
- requests: 判断节点的剩余内存是否满足Pod的内存请求量,以确定是否可以将Pod调度到该节点
- limits: 配置cgroup以限制资源上限
- 磁盘资源(ephemeral storage 容器临时存储):
- requests: 通过定义Pod Spec中的
requests.ephemeral-storage来申请 - limits: 通过定义Pod Spec中的
limits.ephemeral-storage来申请 - 对临时存储的限制不是基于cgroup,而是kubelet定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对pod进行驱逐
- requests: 通过定义Pod Spec中的
Init Container的资源需求
init-container.yaml: 在主容器启动之前去执行,执行一些初始化的工作
可以定义多个init-container,顺序执行
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
initContainers:
- name: init-myservice
image: busybox:1.28
command: [sh, -c, 'echo The app is running! && sleep 10']
containers:
- name: nginx
image: nginx- 当kube-scheduler 调度带有多个init容器的Pod时,只计算cpu.request最多的init容器,而不是计算所有的init容器总和
- 由于多个init容器按照顺序执行,并且执行完成后立即退出,所以申请最多的资源init容器中的所需资源,就可以满足所有init容器的需求
- kube-scheduler在计算该节点被占用的资源时,init容器的资源依然会被纳入计算。因为init容器在特定情况下可能会被再次执行,比如由于更换镜像而引起的sandbox重建时。
limit-range
当用户不想定资源,但是同时需要在这个namespace中给一个默认资源来限制能用的资源上限
limit-range.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Containernginx-without-resource.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginxkubectl apply -f limit-range.yaml
kubectl apply -f nginx-without-resource.yaml最终建出的pod就会存在资源需求
resources:
limits:
memory: 512Mi
request:
memory: 256Minode-selector
node-selector.yaml
仅会调度到label中存在distype=ssdlabel的node上
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
disktype: ssdnode-affinity
NodeAffinity目前支持两种
- 硬亲和: requiredDuringSchedulingIgnoredDuringExecution == node-selector
- 软亲和: preferredDuringSchedulingIgnoredDuringExecutio
下面的例子代表
- 调度到包含标签
kubernets.io/e2e-az-name并且值为e2e-sz1或e2e-az2的Node上 - 优选带有标签
another-node-label-key=another-node-label-value的Node
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecutio:
- weight: 1
preference:
matchExperssions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: gcr.io/google_conatiners/pause:2.0
imagePullPolicy: IfNotPresentpod-affinity
PodAffinity基于Pod的标签来选择Node,仅调度到满足条件Pod所有的Node上,支持podAffiniy和podAntiAffinity
下面的例子代表
- 寻找在同一个可用区中,调度到包含标签
security并且值为S1的pod所在的Node上 - 不共处同一个节点,且尽量避开带有标签
security并且值为S2的pod所处的Node上
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
labels:
app: pod-affinity-pod
spec:
containers:
- name: with-pod-affinity
image: gcr.io/google_conatiners/pause:2.0
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zone # 设置亲和范围在同一个可用区
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname # 设置亲和范围为同一个节点Taints和Tolerations
Taints和Tolerations用于保证Pod不被调度到不合适的Node上,
目前支持的Taint类型:
- NoSchedule: 新的Pod不调度到该Node上,不影响正在运行Pod;
- PreferNoSchedule: soft版的NoSchedule,尽量不调度到该Node上;
- NoExecute: 新的Pod不调度到该Node上,并且删除(evict)已在运行的Pod。Pod可以增加一个时间(tolerationSeconds);
当Pod的Tolerations 匹配 Node的所有Taints时,就可以调度到该Node上;
Taint node
kubectl taint nodes cadmin for-special-user=cadmin:NoSchedulenginx-without-taint.yaml 无法被调度到cadmin这个node上
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginxnginx-with-taint.yaml 可以被调度到cadmin这个node上
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
tolerations:
- key: for-special-user
operator: Equal
value: cadmin
effect: NoScheduleUntaint node
kubectl taint nodes cadmin for-special-user=cadmin:NoSchedule-多租户kubernets-计算资源隔离
Kubernetes 集群一般是通用集群,可被所有用户共享,用户无需关心计算节点细节。 但往往某些自带计算资源的客户要求:
- 带着计算资源加入 Kubernetes 集群
- 要求资源隔离 实现方案:
- 将要隔离的计算节点打上 Taints
- 在用户创建创建 Pod 时,定义 tolerations 来指定要调度到 node taints
❓该方案有漏洞吗?如何堵住?
- 其他用户如果可以 get nodes 或者 pods,可以看到 taints 信息,也可以用相同的 tolerations 占用资源。
- 不让用户 get node detail?
- 不让用户 get 别人的 pod detail?
- 企业内部,也可以通过规范管理,通过统计数据看谁占用了哪些 Node;
- 数据平面上的隔离还需要其他方案配合。
优先级调度
从v1.8开始,kube-scheduler支持定义Pod的优先级,从而保证高优先级的Pod优先调度。开启方法为:
- apiserver配置:
--feature-gates=PodPriority=true和--runtime-config=scheduling.k8s.io/v1aplha1=true - kube-scheduler配置:
--feature-gates=PodPriority=true
Caution
在一个并非所有用户都是可信的集群中,恶意用户可能以最高优先级创建 Pod, 导致其他 Pod 被驱逐或者无法被调度。 管理员可以使用 apiserver-ResourceQuota 来阻止用户创建高优先级的 Pod。 参见 默认限制优先级消费。
PriorityClass
示例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false # 添加一个将 globalDefault 设置为 true 的 PriorityClass 不会改变现有 Pod 的优先级。 此类 PriorityClass 的值仅用于添加 PriorityClass 后创建的 Pod。
preemptionPolicy: Never # 不可以抢占其他低优先级的Pod的资源,直到有足够的可用资源才可以被调度
description: 此优先级类应仅用于 XYZ 服务 Pod。preemptionPolicy
- Never: 不可以抢占其他低优先级的Pod的资源,直到有足够的可用资源才可以被调度
- PreemptLowerPriority: 这将允许该 PriorityClass 的 Pod 抢占较低优先级的 Pod
为Pod设置priority:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。并且在整个集群中还可以同时运行多个调度器实例,通过 pod.Spec.schedulerName 来选择使用哪一个调度器(默认使用内置的调度器)。
生产的一些经验

常用命令
kubectl drain: 从节点安全地逐出所有Pod, 并将该节点标记为不可调度
kubectl cordon: 将节点标记为不可调度, 即该节点将会被打上node.kubernetes.io/unschedulable=:NoSchedule的污点
kubectl uncordon: 将节点标记为可调度controller-manager
控制器工作流程
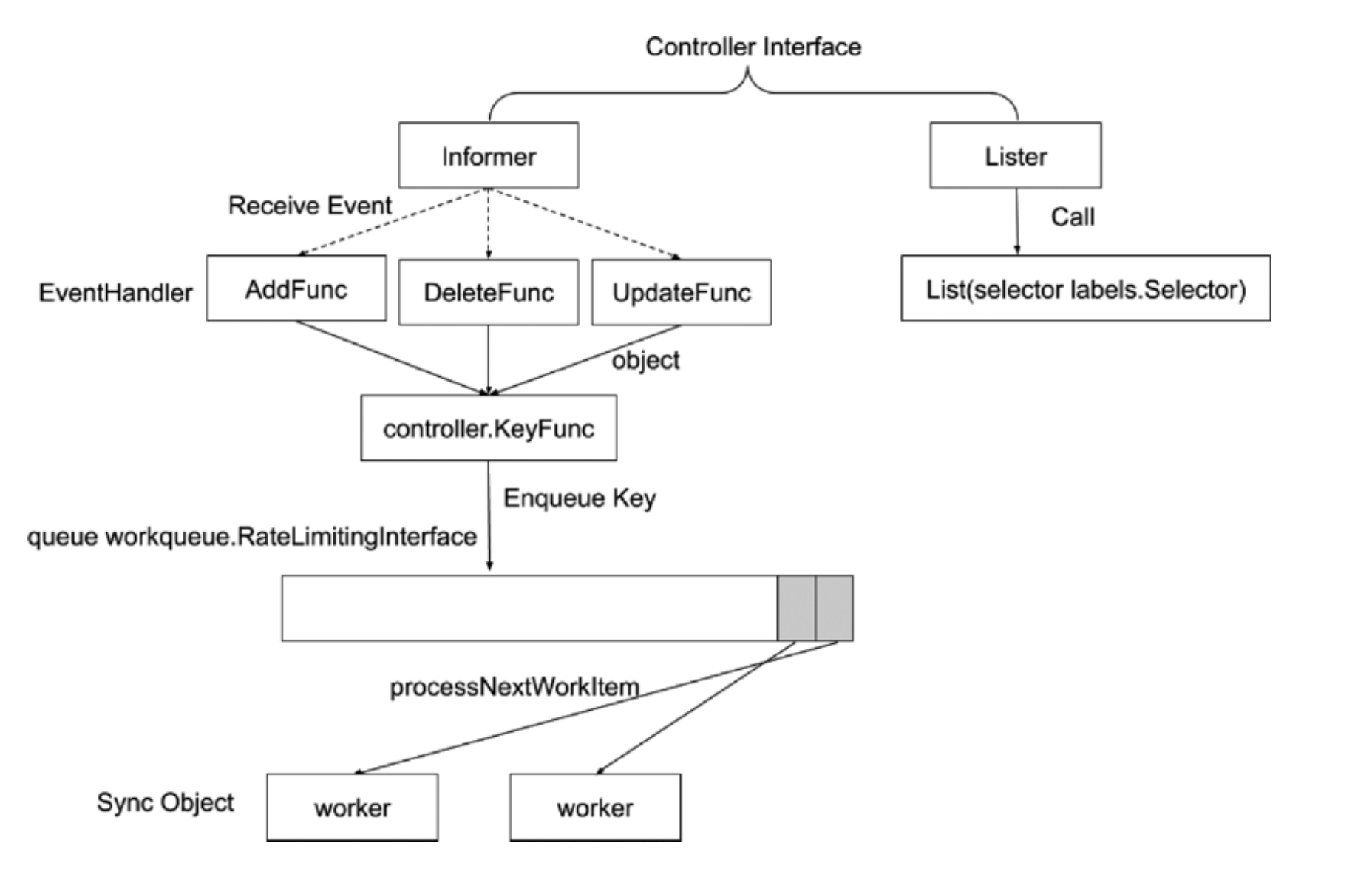
- informer: 消息通知机制的接口
- Lister: 负责发送当前状态
eventHandler发送过来的是一个完整的对象,大部分控制器会拿这个对象的keyFunc(namespace + name)放入一个queue中,再由worker从这个队列中取出key,因为没有对象的完整信息,所以会通过Lister接口去取对象的完整信息
❓为什么把key放入队列中而不是直接放入一个完整对象?
假设一个对象频繁变更,一方面会导致这个队列占用的内存空间增大,二是每次都将变成一个事件交由worker去处理。只存入key,就能保证worker处理这个key的时候只需要关注最终状态,而无需关注中间频繁变更的状态
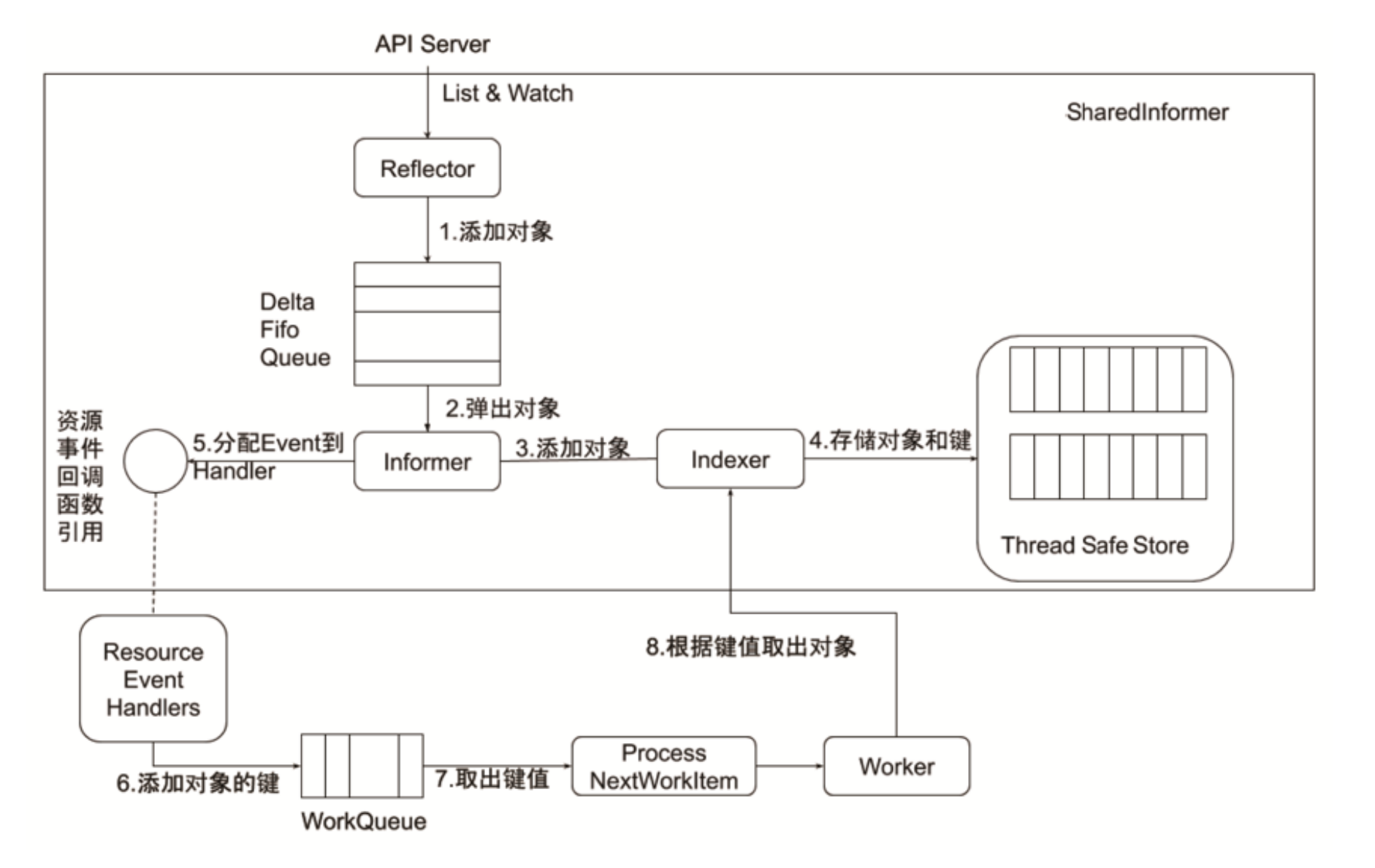
Informer的内部机制
控制器的协同工作原理
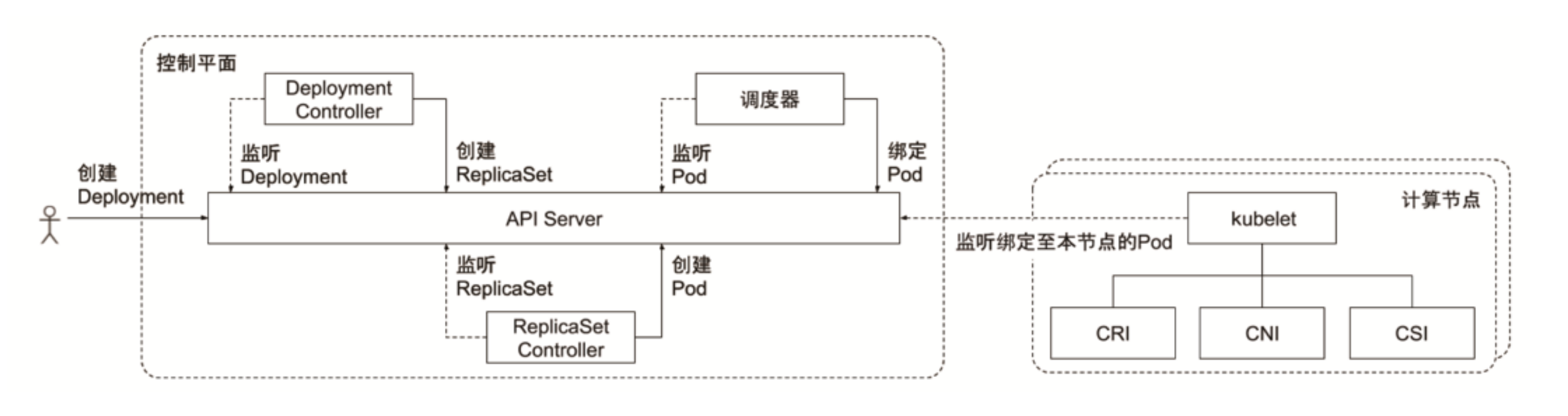
- Deployment里面有额外的updateStrategy
- ReplicaSet定义的是副本级
- Pod定义的是应用实例
Deployment 控制器将 pod-template-hash 标签添加到 Deployment 所创建或收留的每个 ReplicaSet 。
此标签可确保 Deployment 的子 ReplicaSets 不重叠。 标签是通过对 ReplicaSet 的 PodTemplate 进行哈希处理。 所生成的哈希值被添加到 ReplicaSet 选择算符、Pod 模板标签,并存在于在 ReplicaSet 可能拥有的任何现有 Pod 中。
通用Controller
- Job Controller: 处理 job。
- Pod AutoScaler: 处理 Pod 的自动缩容/扩容。
- RelicaSet: 依据 Replicaset Spec 创建 Pod。
- Service Controller: 为 LoadBalancer type 的 service 创建 LBVIP。
- ServiceAccount Controller: 确保 serviceaccount 在当前 namespace 存在。
- StatefulSet Controller: 处理 statefulset 中的 Pod。
- Volume Controller: 依据 PV spec 创建 volume。
- Resource quota Controller: 在用户使用资源之后,更新状态。
- Namespace Controler:保证 namespace删除时,该 namespace 下的所有资源都先被删除
- Replication Controller:创建 RC 后,负责创建 Pod。
- Node Controller: 维护 node 状态,处理 evict 请求等。
- Daemon Controller:依据 damonset 创建 Pod。
- Deployment Controller:依据 deployment spec 创建 replicaset.。
- Endpoint Controller:依据 service spec 创建 endpoint,依据 podip 更新 endpoint。
- Garbage Collector:处理级联删除,比如删除 deployment 的同时删除 replicaset 以及 Pod。
- Cronjob Controler:处理 cronjob。
Garbage Collector
通过定义ownerReference定义对象所属哪个对象,以此来建立各个对象之间的父子关系,通过这层父子关系达到集联删除的目的
apiVersion: v1
kind: Pod
metadata:
ownerReferences:
- apiVersion: apps/v1
controller: true
blockOwnerDeletion: true
kind: ReplicaSet
name: my-repset
uid: d9607e19-f88f-11e6-a518-42010a800195Cloud Controller Manager
Cloud Controller Manager 自 Kubernetes1.6 开始,从 kube-controller-manager 中分离出来,主要因为 Cloud Controller Manager 往往需要跟企业 cloud 做深度集成,release cycle 跟Kubernetes 相对独立。
与 Kubernetes核心管理组件一起升级是一件费时费力的事。
- 认证授权:企业 cloud 往往需要认证信息,Kubernetes 要与 Cloud API 通信,需要获取 cloud系统里的 ServiceAccount;
- cloud controller manager 本身作为一个用户态的 component,需要在Kubernetes 中有正确的 RBAC 设置,获得资源操作权限;
- 高可用:需要通过 leader election 来确保 cloud controller manager 高可用。
- 。
- kubelet 要配置
--cloud-provider=external
- Node controller: 访问 cloud APl,来更新 node 状态; 在 cloud 删除该节点以后,从Kubernetes 删除 node;
- Service controller: 负责配置为 loadbalancer 类型的服务配置 LB VIP
- Route Controller: 在 cloud 环境配置路由
- 可以自定义任何需要的 cloud Controler
生产的一些经验
- 此 kubeconfig 拥有所有资源的所有操作权限,防止普通用户通过
kubectl exec kube-controler-managercat 获取该文件。
确保scheduler和controller的高可用
kubernetes使用了Leader Election来保证同一时刻只存在一个活跃的scheduler或者controller
Kubenetes提供基于configmap和endpoint对象的 leader election 类库(最新版本是lease对象)。
Kubernetes 采用leader election 模式启动 component后,会创建对应 endpoint,并把当前的leader 信息 annotate 到 endponit 上
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderldentity":"minikube", "leaseDurationSeconds":15", acquireTime":"2018-04-05T17:31:29Z", "renewTime:": "2018-04-07T07:18:39Z", "leaderTransitions": 0}'
creationTimestamp: 2018-04-05T17:31:29Z
name: kube-scheduler
namespace: kube-System
resourceVersion: '138930'
selfLink: /api/v1/namespaces/kube-system/endpoints /kube-scheduler
uid: 2d12578d-38f7-11e8-8df0-0800275259e5
subsets: null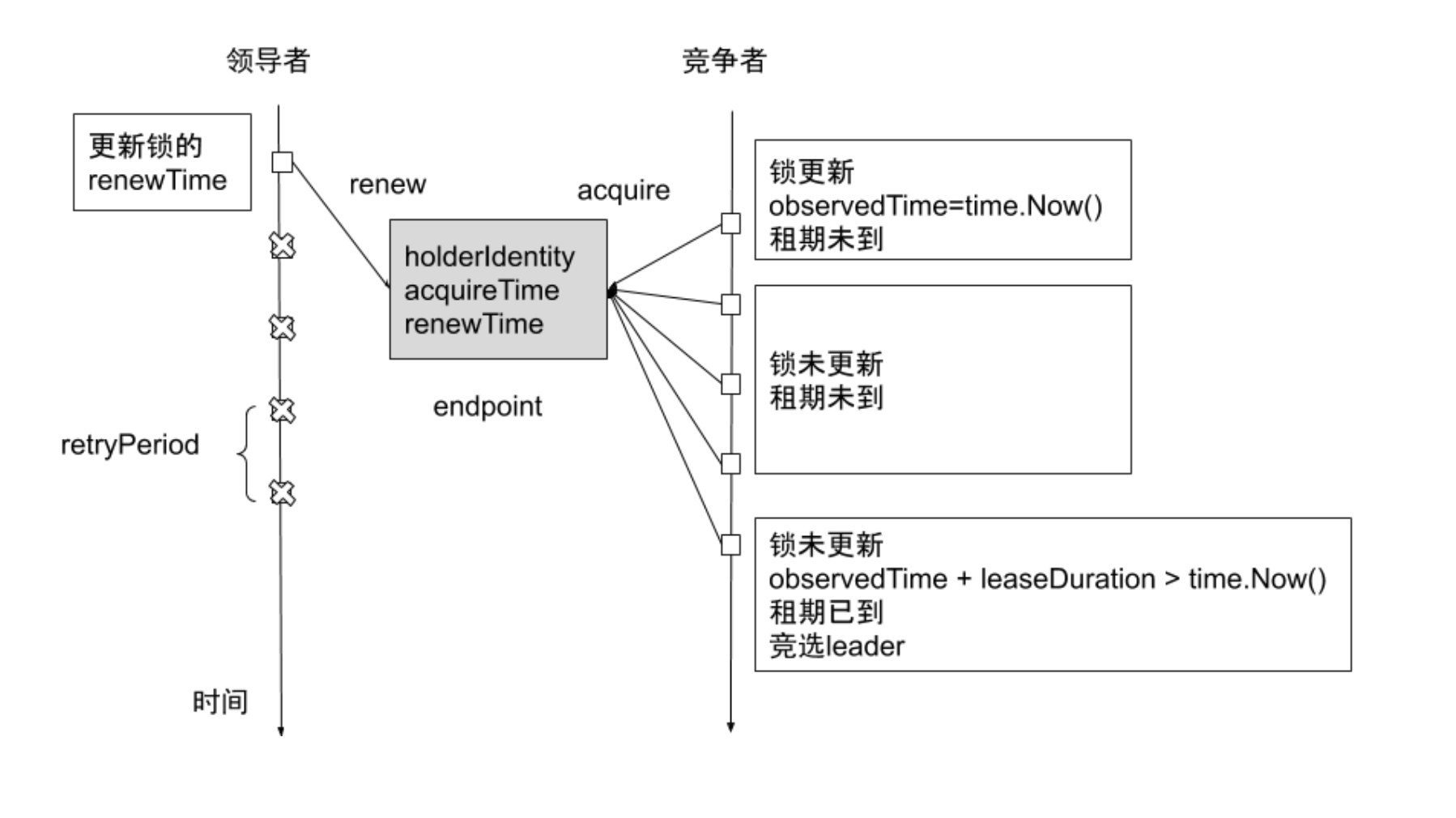
kubelet
kubelet 架构
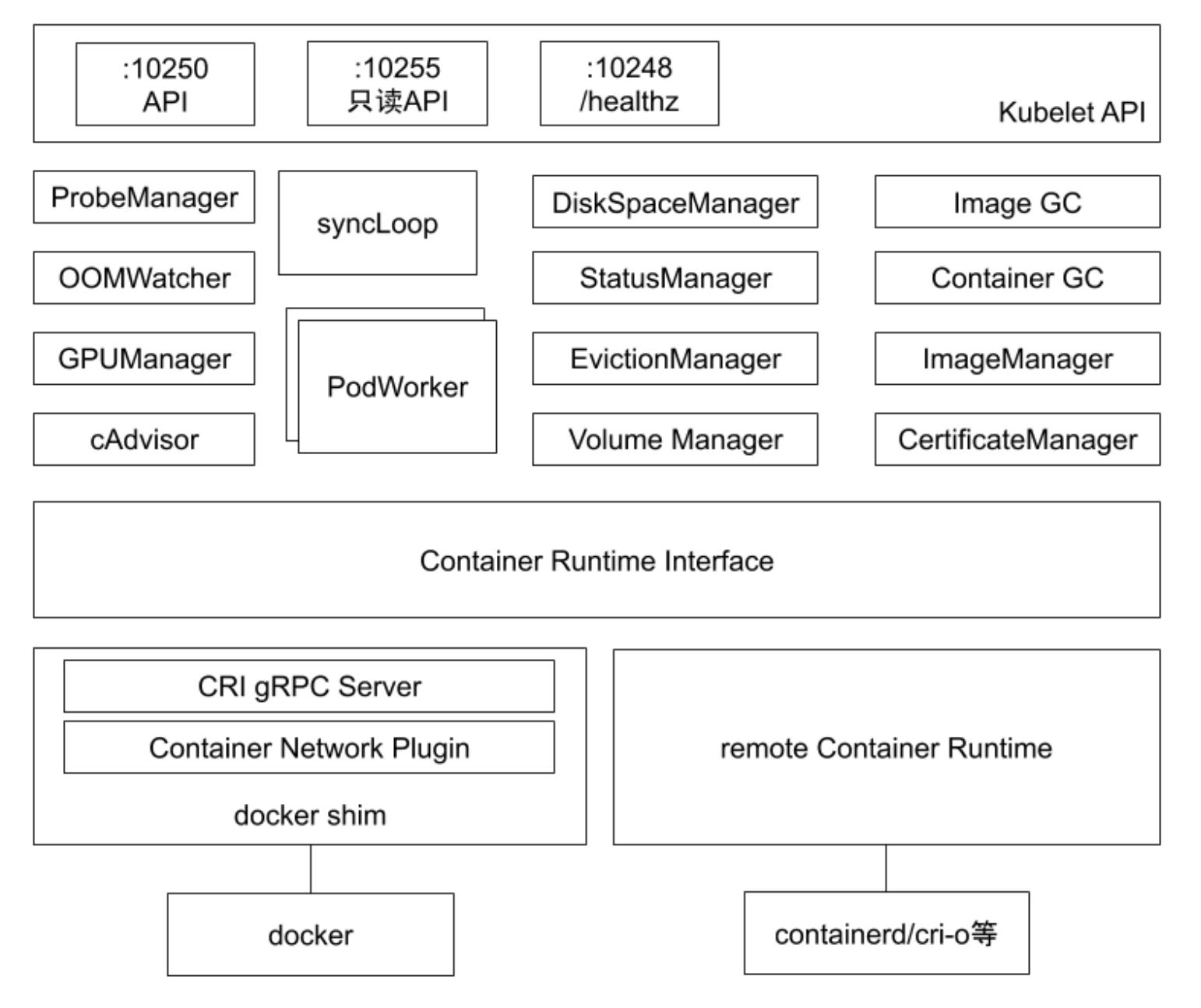
- ProbeManager: 为节点上的Pod做探活的管理器
- OOMWatcher: 监听哪些进程出现了OOM问题,并上报给kubelet
- GPUManager: 管理GPU等扩展设备
- cAdvisor: 基于cgroup技术,获取节点上运行的应用的资源状态
- DiskSpaceManager: 管理节点的磁盘空间大小、容器临时空间
- StatusManager: 管理节点的状态
- EvictionManager: 监听当前节点的内存使用情况,内存如果已经达到监听的水位,会按照既定策略把低优先级且占用内存量超过预设值的业务做驱逐
- VolumeManager: 挂载磁盘、存储卷
- Image GC: 清理节点的不活跃image
- Container GC: 清除已经退出的容器
- ImageManager: 镜像管理
- CertificateManager: 管理证书
kubelet管理Pod的核心流程
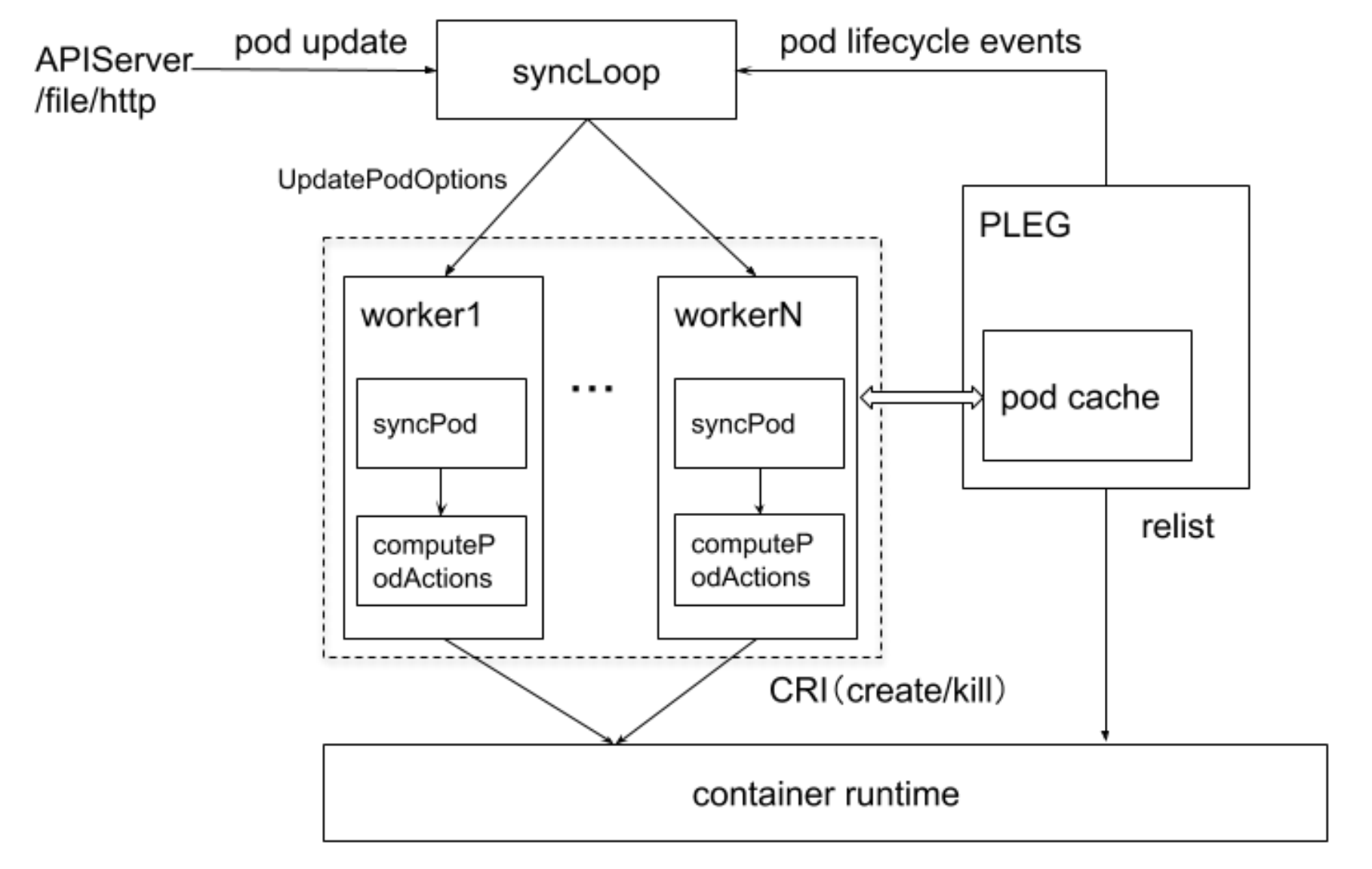
syncLoop负责监听Pod的状态变化,并存储到UpdatePodOptions中
每个worker从队列中获取Pod变更的事件清单,针对每个Pod做syncPod的操作,其中syncPod里面最重要的一个行为就是computePodAction(计算针对Pod需要采取什么样的行为),最终通过CRI的接口去实现
PLEG主要负责Pod状态的上报,PLEG内部维护了pod cache, PLEG会定期往container runtime内部去发送一个list的操作,来获取当前节点上的Pod清单,在内部做汇聚,最终通过pod lifeccle events发回上报给api-server
Caution
- 如果container runtime不响应,relist会失败,最终就会导致状态无法上报
- 如果节点上的exit container非常多,可能会导致relist超时,最终也会导致状态无法上报
kubelet 职责
核心职责
- 接收并执行master发来的指令
- 管理Pod及Pod中的容器
- 每个kubelet进程会在API Server上注册节点自身信息,定期向master节点汇报节点的资源使用情况,并通过cadvisor监控节点和容器的资源
节点管理
主要是节点自注册和节点状态更新
- kubelet 可以通过设置启动参数
--register-node来确定是否向API Server注册自己 - 如果kubelet没有选择自注册模式,则需要用户自己配置Node资源信息,同时需要告知kubelet集群上的API Server位置
- kubelet在启动时通过API Server注册节点信息,并定时向API Server发送节点新信息,API Server在接收到新消息后,将信息写入etcd
Pod管理
获取Pod清单
- 文件(static pod): 启动参数–config 指定的配置目录下的文件(默认 /etc/Kubernetes/manifests/)。该文件每20秒重新检查一次(可配置)
- HTTP endpoint(URL): 启动参数
--manifest-url设置。每 20 秒检查一次这个端点(可配置) - API Server: 通过 API Server 监听 etcd 目录,同步 Pod 清单。
- HTTP Server: kubelet 侦听 HTTP 请求,并响应简单的 API 以提交新的 Pod 清单。
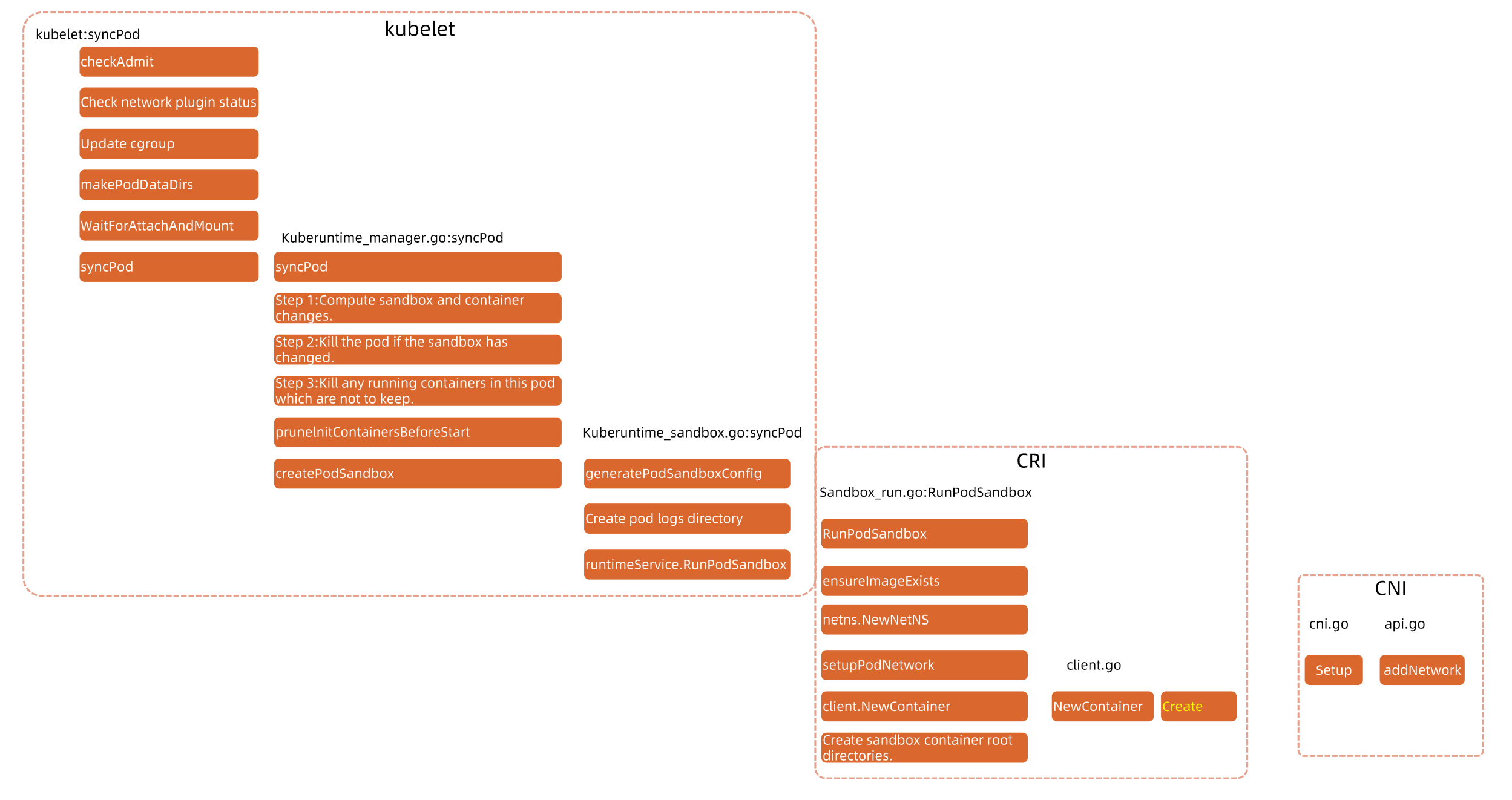
Pod启动流程
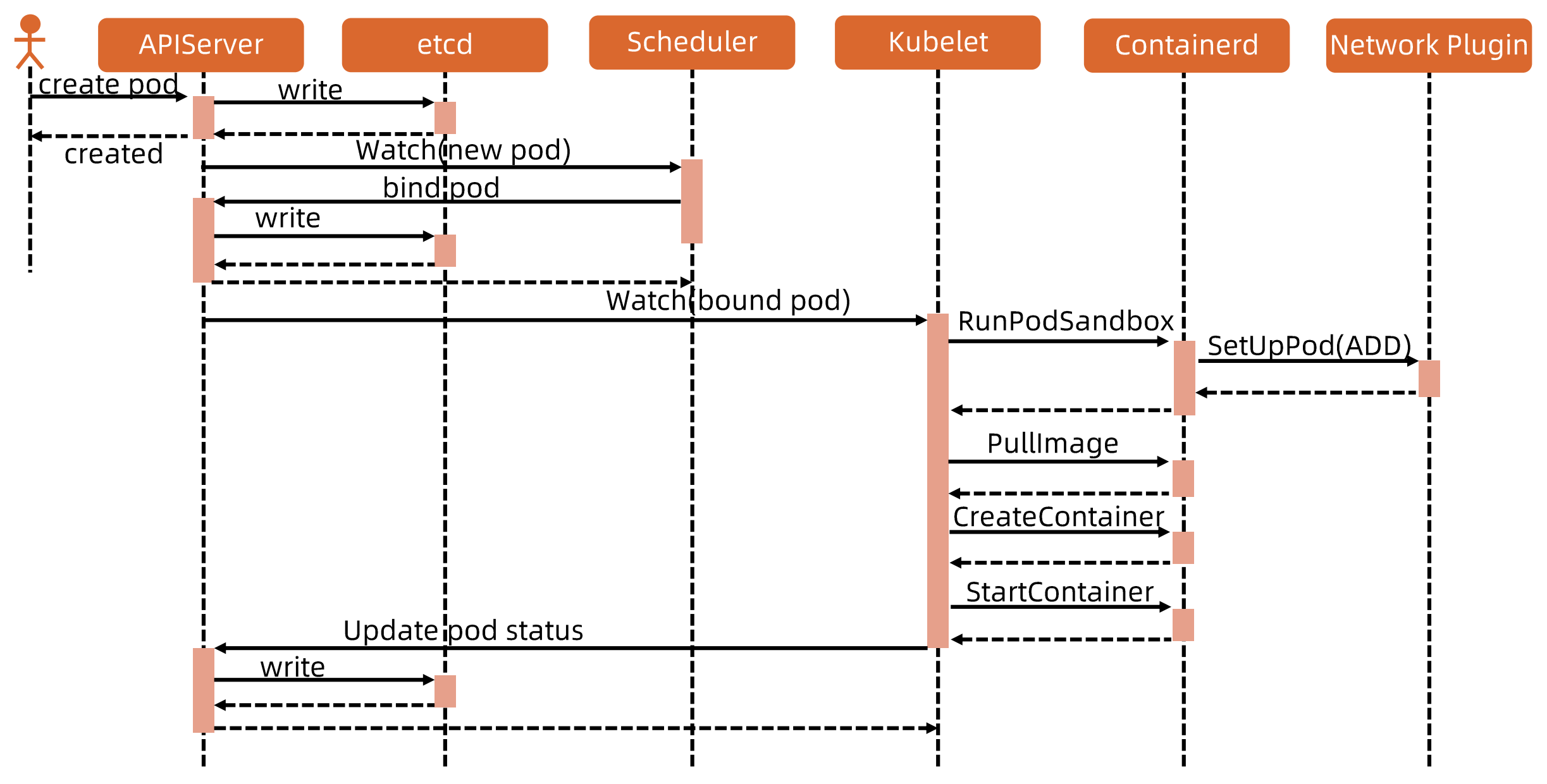
sandBoxContainer: pause容器存在的意义
- 如果将容器进程直接加入到网络namespace,可能因为容器进程本身的不稳定,而导致需要频繁配置网络,加重操作系统负担
- 容器进程的启动有时依赖网络资源的就绪,sandBoxContainer负责提供这个底座
细节版本:
Tip
衍生面试题: Pod启动的时候,CRI、CNI、CSI的启动顺序是怎么样的? 谁先谁后
answer: CSI(等待存储attach到node,用于启动容器挂载) -> CRI(run sandBoxContainer) -> CNI(setup pod network) -> 用户容器启动
CRI
容器运行时 (Container Runtime),运行于 Kubernetes集群的每个节点中,负责容器的整个生命周期。其中 Docker是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。
为了解决这些容器运行时和 Kubernetes 的集成问题,在Kubernetes 1.5版本中,社区推出了 CRI(Container Runtime Interface,容器运行时接口)以支持更多的容器运行时。
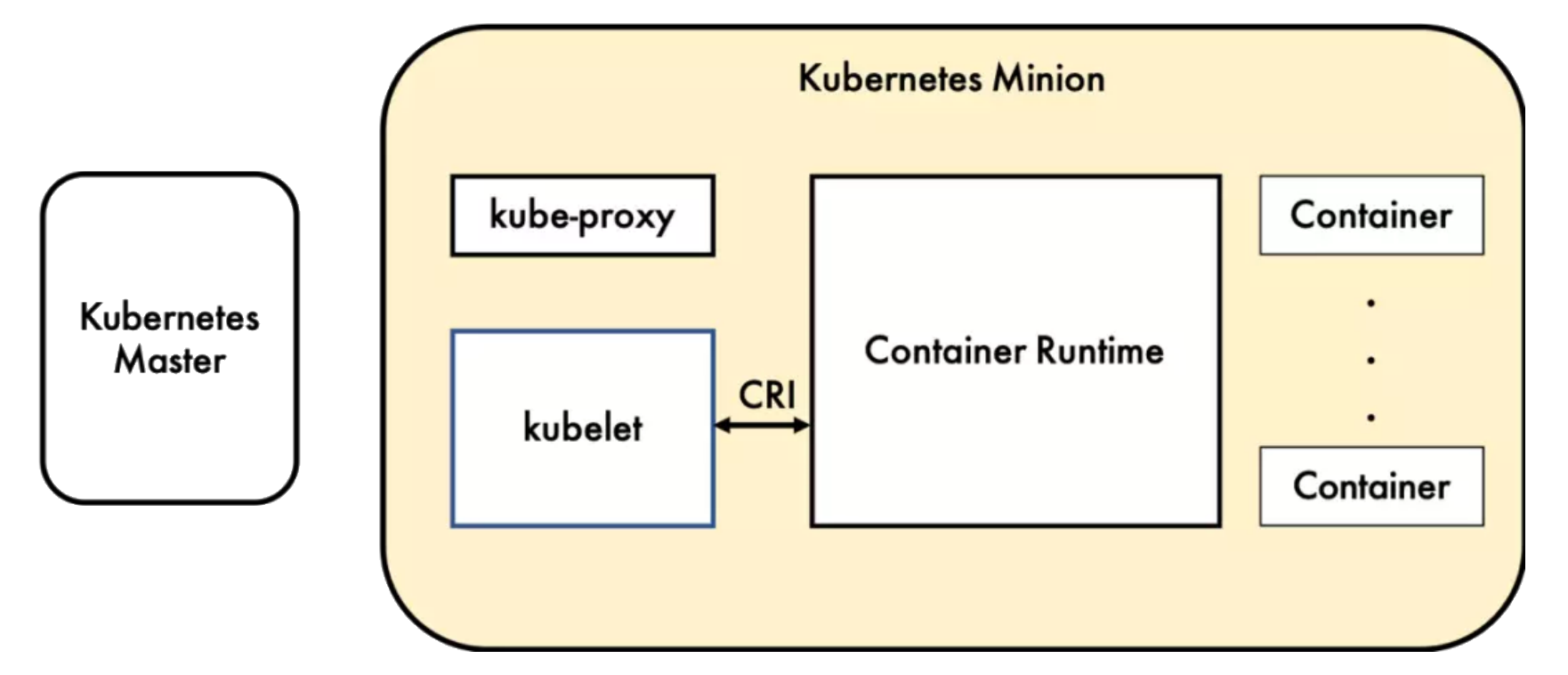
容器运行时通信。
运行时层级
OCI(Open Container Initiative, 开放容器计划)定义了容器相关的行业标准
- 镜像规范(Image Specification)
- 运行时规范(Runtime Specification)
- 促进和标准化内容的分发(Distribution Specification)
CRI包括两类服务: 。 –
- 镜像服务提供下载、检查和删除镜像的远程程序调用。
- 运行时服务包含用于管理容器生命周期,以及与容器交互的调用(exec/attach/port-forward)的远程程序调用。
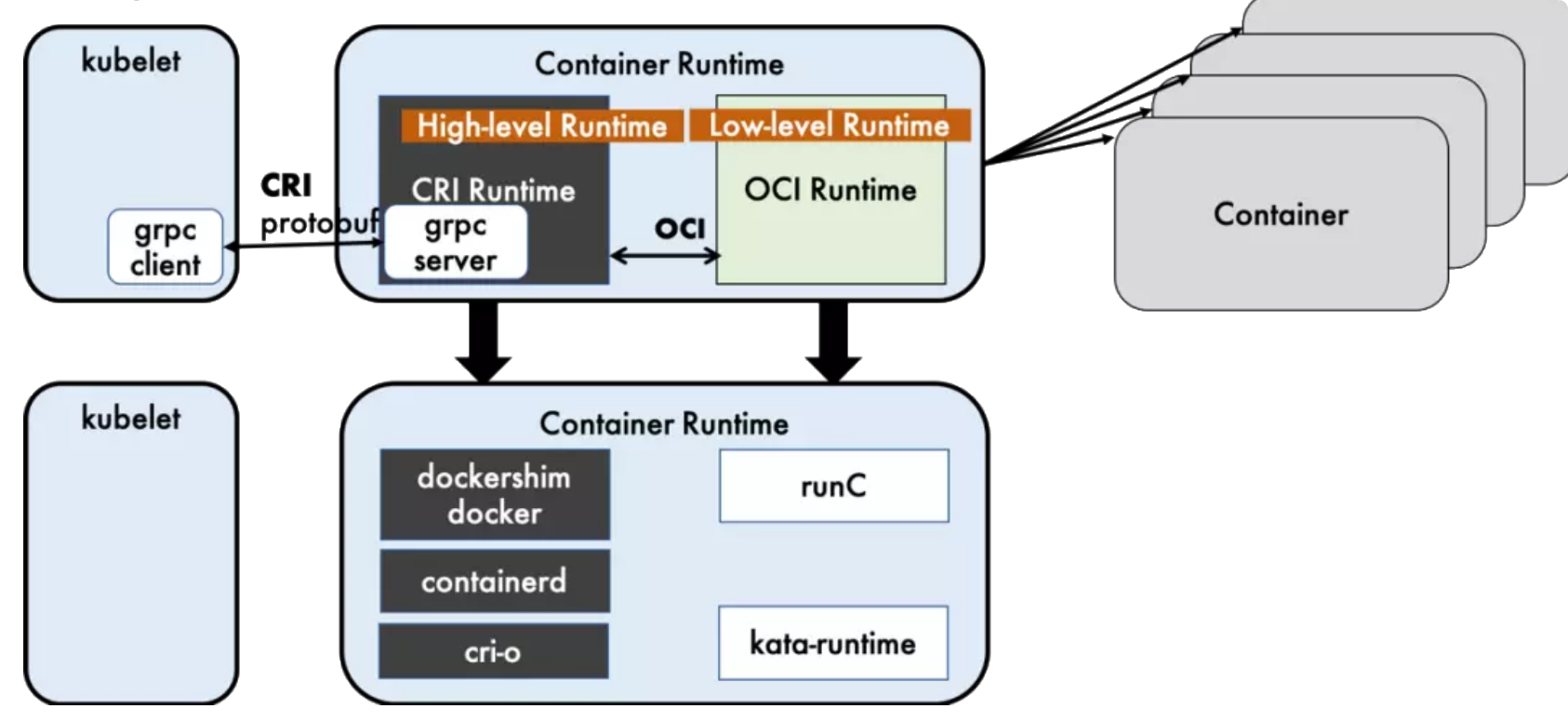
container runtime分为
- High-level runtime: 例如Dockershim, containerd, CRI-O
- Low-level runtime: 例如runC, kata-runtime
/var/lib/docker/overlay2)如何为新容器设置命名空间和cgroup,以及挂载根文件系统等操作,都是在这里定义的Note
Docker 内部关于容器运行时功能的核心组件是 containerd,后来 containerd 也可直接和 kubelet 通过 CRI 对接,独立在 Kubernetes 中使用。
相对于 Docker 而言,containerd 减少了 Docker 所需的处理模块 Dockerd 和 Docker-shim,并且对Docker 支持的存储驱动进行了优化,因此在容器的创建启动停止和州除,以及对镜像的拉取上,都具有性能上的优势。
架构的简化同时也带来了维护的便利。当然 Docker 也具有很多 containerd 不具有的功能,例如支持zfs存储驱动,支持对日志的大小和文件限制,在以 overlayfs2 做存储驱动的情况下,可以通过xfs_quota来对容器的可写层进行大小限制等。
尽管如此,containerd 目前也基本上能够满足容器的众多管理需求,所以将它作为运行时的也越来越多。
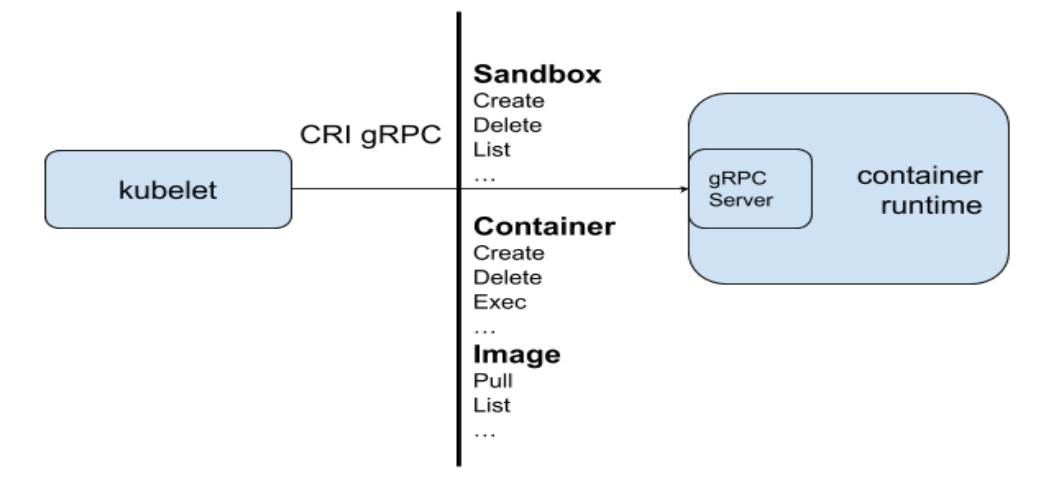 kubelet和CRI的关系
kubelet和CRI的关系
CRI 规范细节
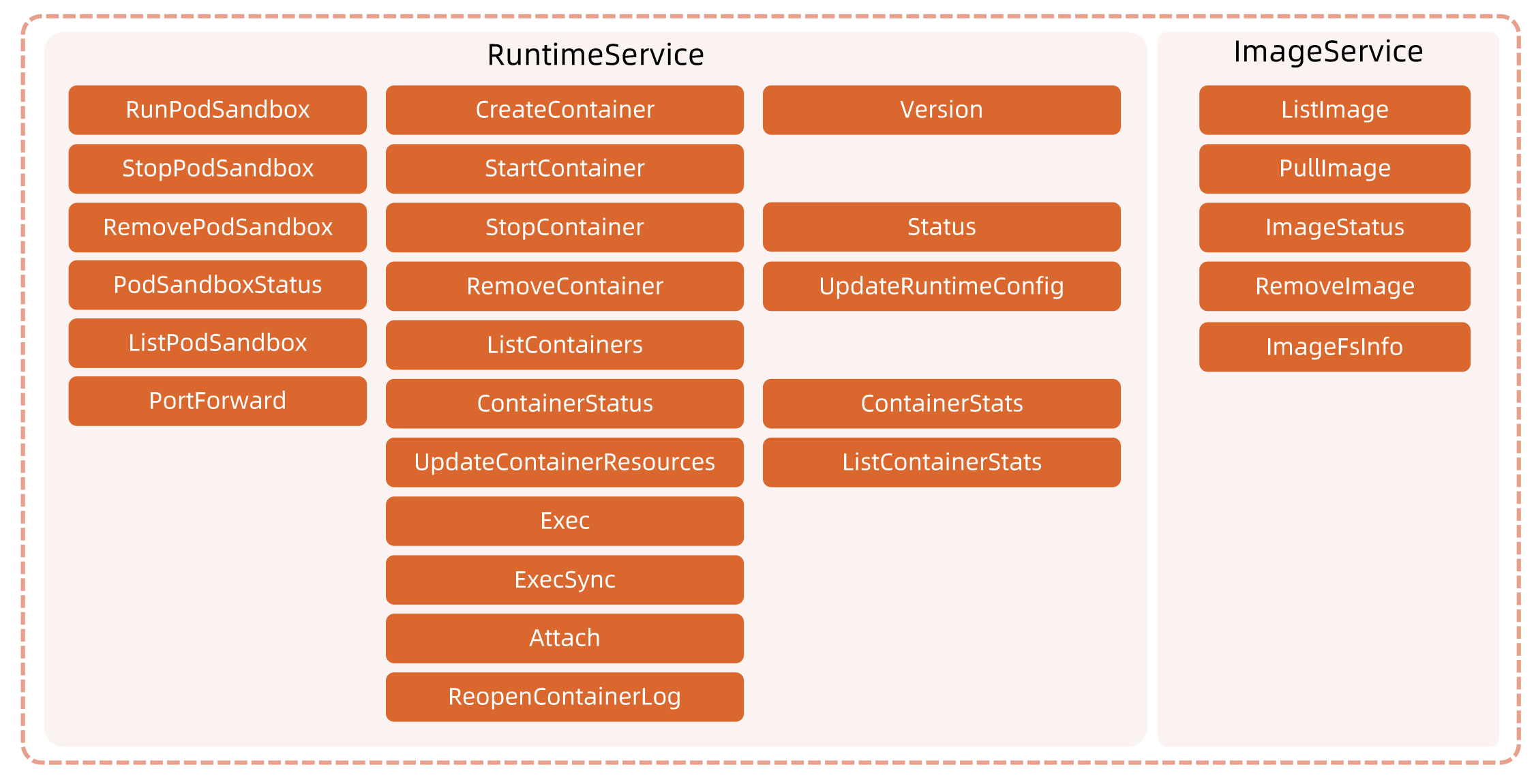
开源CRI 比较
Docker 的多层封装和调用,导致其在可维护性上略逊一筹,增加了线上问题的定位难度; 几乎除了重启 Docker,我们就毫无他法了。
containerd 和 CRI-O 的方案比起 Docker 简洁很多。
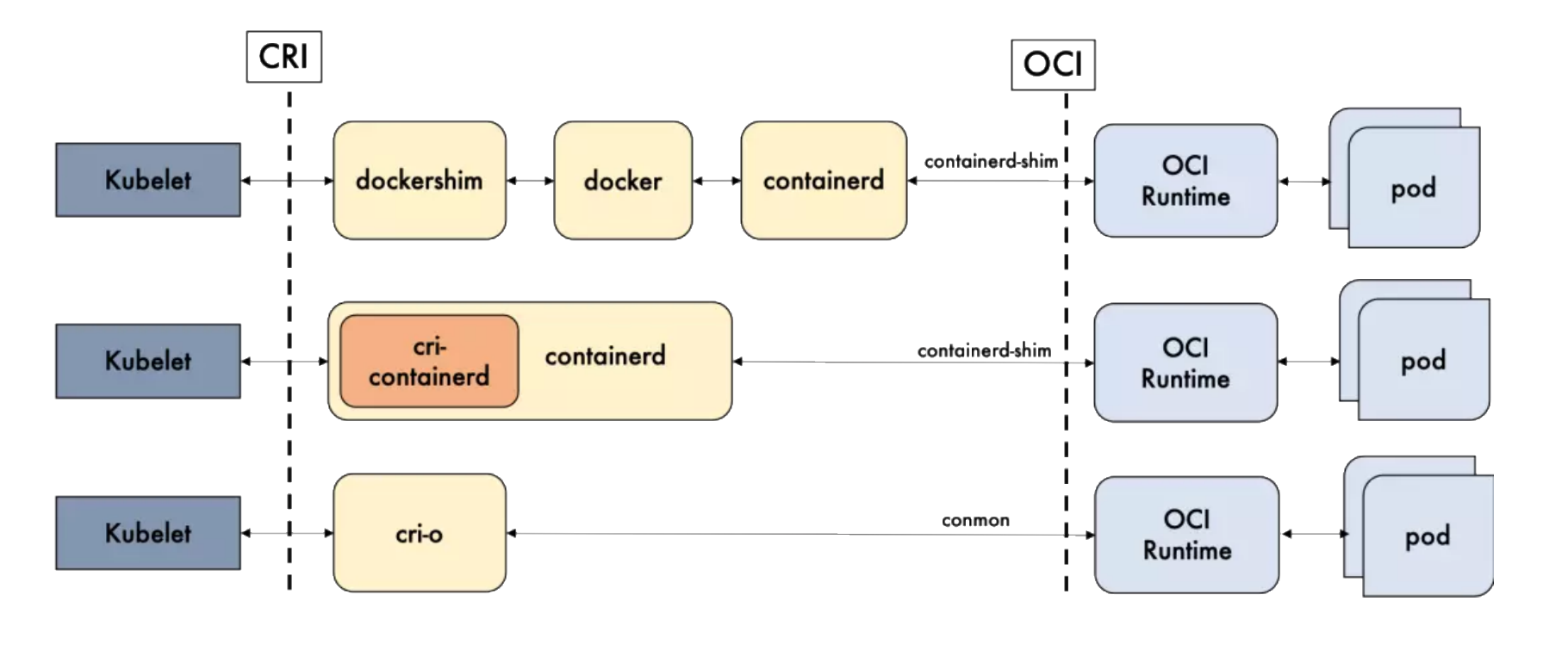
Docker和Containerd的差异
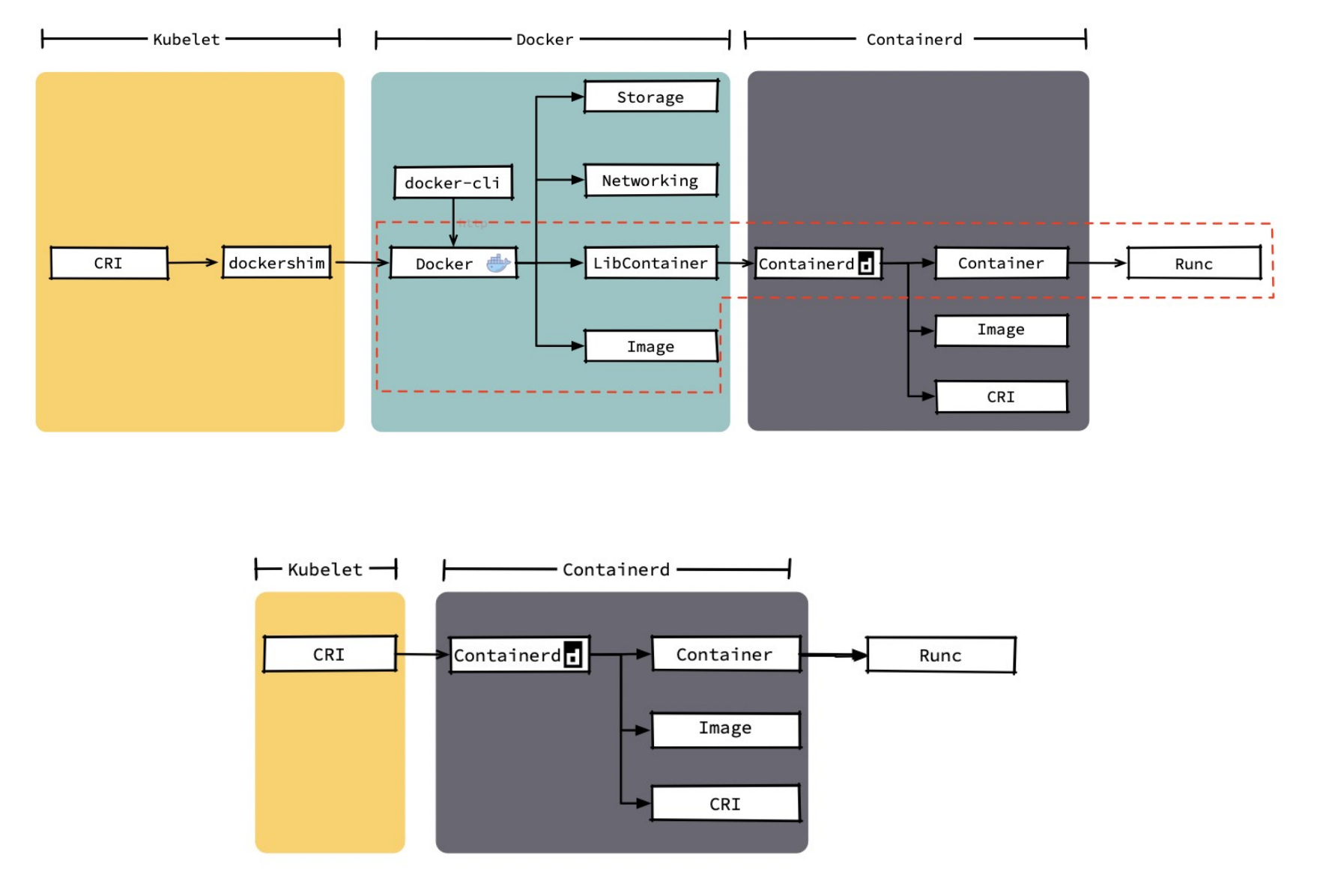
多种运行时性能比较
containerd 在各个方面都表现良好,除了启动容器这项。
从总用时来看,containerd的用时还是要比CRI-O要短的。
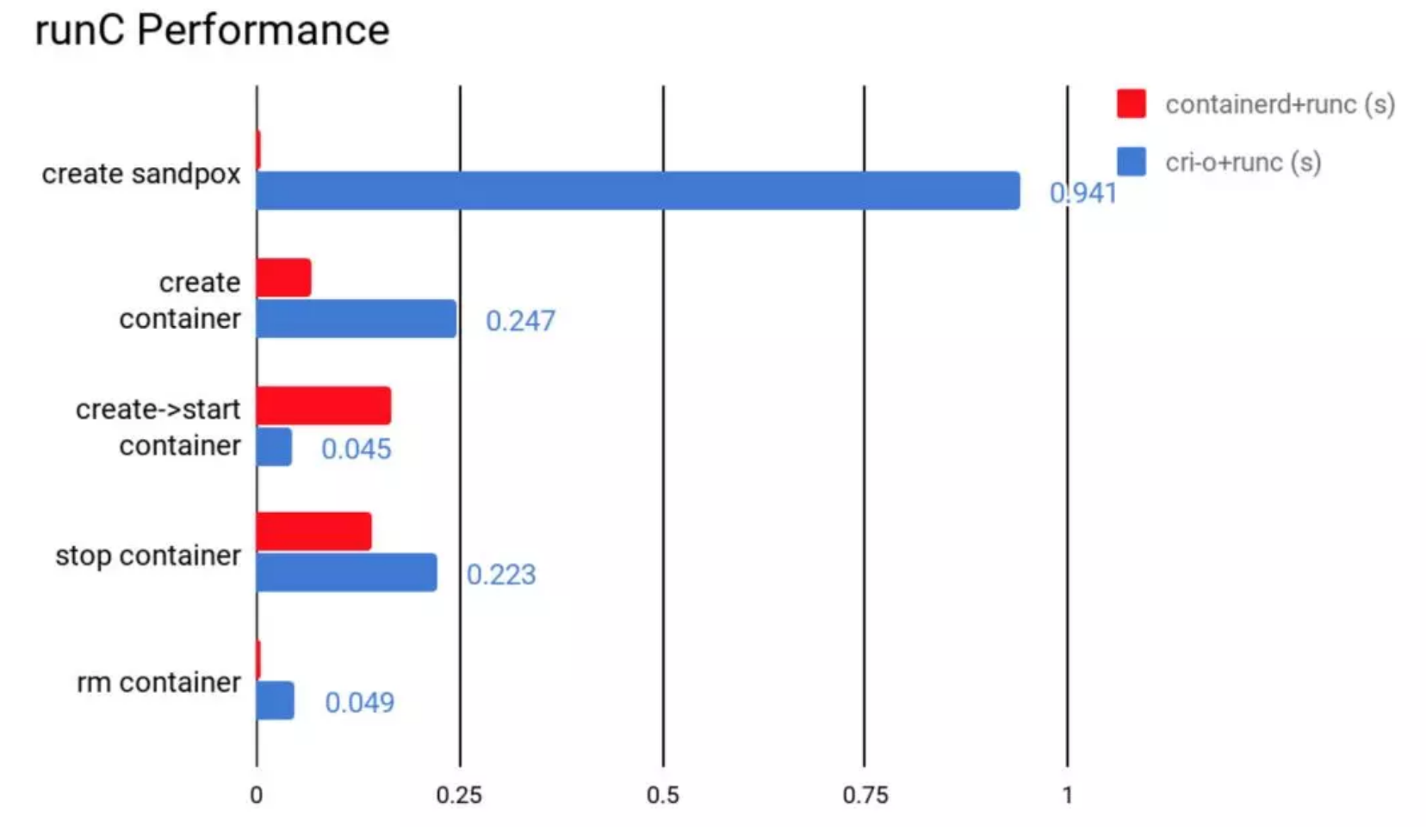
运行时优劣对比
- 功能性: containerd和CRI-O都符合CRI和OCI的标准
- 稳定性: containerd略胜一筹
- 性能: container胜出
| containerd | CRI-O | 备注 | |
|---|---|---|---|
| 性能 | 更优 | 优 | CRI与OCI兼容 |
| 稳定性 | 稳定 | 未知 |
docker迁移至containerd
- Stop service
systemctl stop kubelet
systemctl stop docker
systemctl stop containerd- Create containerd config folder
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml- Update default config
# 直接在配置文件中修改镜像
vim /etc/containerd/config.toml
sed -i s#k8s.gcr.io/pause:3.5#registry.aliyuncs.com/google_containers/pause:3.5#g /etc/containerd/config.toml
sed -i s#'SystemdCgroup = false'#'SystemdCgroup = true'#g /etc/containerd/config.toml- Edit kubelet config and add extra args
# 或者启动时指定参数
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Environment="KUBELET_EXTRA_ARGS=--container-runtime=remote --container-runtime-endpoint=unix:///run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5"- Restart
systemctl daemon-reload
systemctl restart containerd
systemctl restart kubelet- Config crictl to set correct endpoint
cat << EOF | sudo tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
EOFcrictl一些常用指令
crictl pods: 列出sandbox的容器进程crictl ps: 列出用户的容器进程crictl images: 列出镜像crictl inspectp: 查看sandbox进程信息crictl inspect: 查看用户容器进程信息crictl inspecti: 查看镜像的具体信息
CNI
- 所有的pod能够不通过NAT就能互相访问
- 所有的节点能够不通过NAT就能互相访问
- 容器内看到的IP地址和外部组件看到的容器IP是一样的
Kubernetes 的集群里,IP地址是以Pod为单位进行分配的,每个 Pod都拥有一个独立的1P 地址。每个Pod内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的 IP 地址、网络设备、配置等都是共享的。
也就是说,。在Kubernetes 中,提供了一个轻量的通用容器网络接口 CNI (Container Network Interface),专门用于设置和删除容器的网络连通性。容器运行时通过CNI 调用网络插件来完成容器的网络设置。
CNI 插件分类和常见插件
- IPAM: IP地址分配
- 主插件: 网卡设置
- bridge: 创建一个网桥,并把主机端口和容器端口插入网桥
- ipvlan: 为容器添加ipvlan网口
- loopback: 设置loopback网口
- Meta: 附加功能
- portmap: 设置主机端口和容器端口映射
- bandwidth: 利用Linux Traffic Control 限流
- firewall: 通过iptables或者firewalld为容器设置防火墙规则
参考: CNI plugins
CNI 插件运行机制
容器运行时在启动时会从CNI的配置目录中读取JSON格式的配置文件,文件后缀为 ".conf", ".conflist", ".json"。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。
CNI通过可执行文件的直接调用来进行网络配置
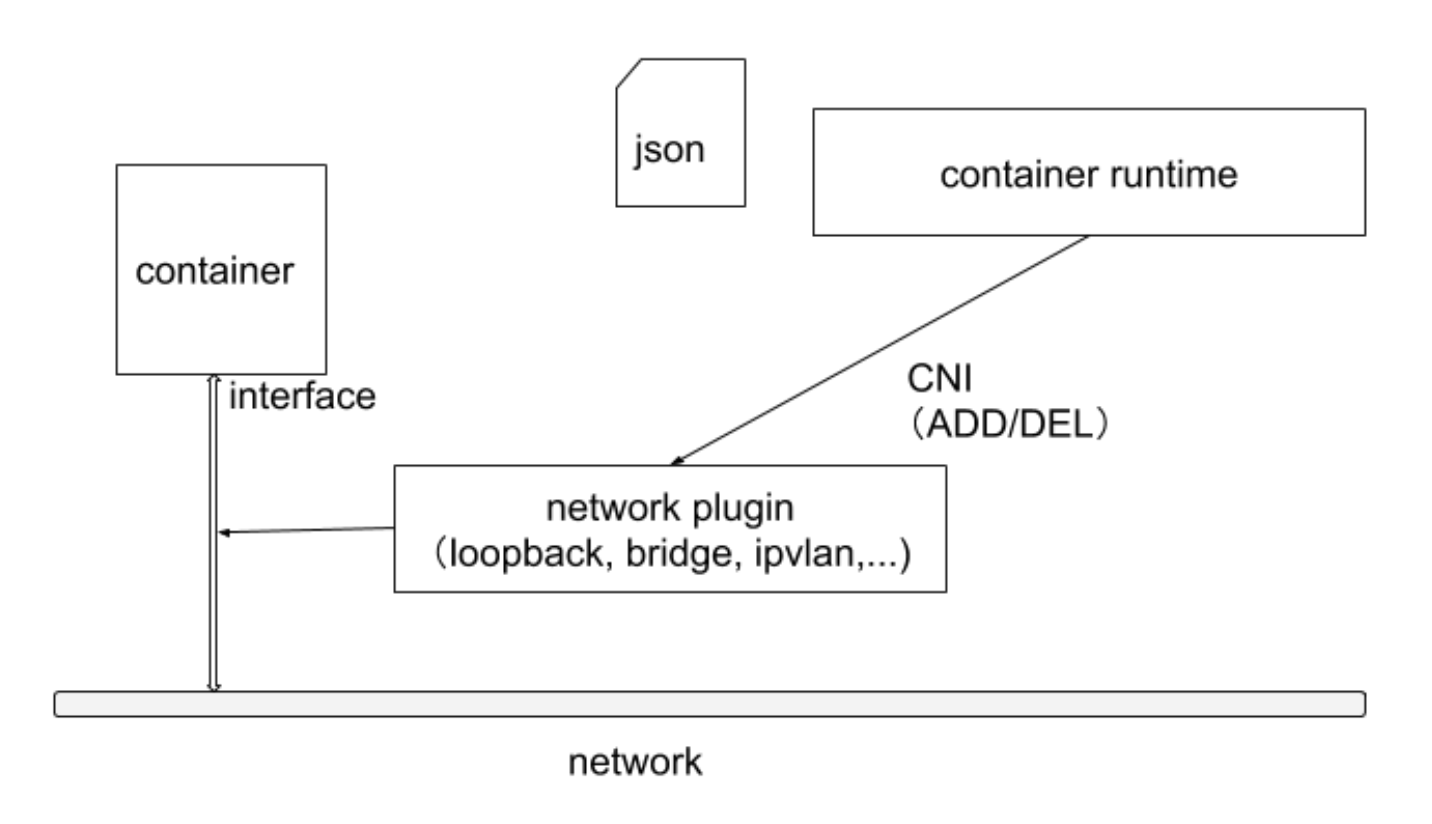
关于容器网络管理,容器运行时一般需要配置两个参数 --cni-bin-dir 和 --cni-conf-dir。有一种特殊情况,kubelet 内置的 Docker 作为容器运行时,是由 kubelet 来查找 CNI插件的,运行插件来为容器 设置网络,这两个参数应该配置在 kubelet 处:
- cni-bin-dir:网络插件的可执行文件所在目录。默认是
/opt/cni/bin。 - cni-conf-dir:网络插件的配置文件所在目录。默认是
/etc/cni/net.d。
CNI 插件设计考量
- 容器运行时必须在调用任何插件之前为容器创建一个新的网络命名空间。
- 容器运行时必须决定这个容器属于哪些网络,针对每个网络,哪些插件必须 要执行。
- 容器运行时必须加载配置文件,并确定设置网络时哪些插件必须被执行。
- 网络配置采用JSON 格式,可以很容易地存储在文件中。
- 容器运行时必须按顺序执行配置文件里相应的插件。
- 在完成容器生命周期后,容器运行时必须按照与执行添加容器相反的顺序执行插 件,以便将容器与网络断开连接。
- 容器运行时被同一容器调用时不能并行操作,但被不同的容器调用时,允许并行 操作。
- 容器运行时针对一个容器必须按顺序执行 ADD 和 DEL 操作,ADD 后面总是跟着 相应的 DEL。DEL 可能跟着额外的 DEL,插件应该允许处理多个 DEL。
- 容器必须由 ContainerID 来唯一标识,需要存储状态的插件需要使用网络名称、容器ID 和网络接口组成的主key 用于索引。
- 容器运行时针对同一个网络、同一个容器、同一个网络接口,不能连续调用两次 ADD 命令。
ContainerNetworking 组维护了一些CNI插件,包括网络接口创建的 bridge、 ipvlan、 loopback、macvlan、 ptp、 host-device 等,IP 地址分配的 DHCP、 host-local 和 static,其他的 Flannel、tunning、 portmap、 firewall等。
社区还有些第三方网络策略方面的插件,例如 Calico、Cilium 和 Weave 等。可用选项的多样性意味着大多数用户将能够找到适合其当前需求和部署环境的 CNI 插件,并在情况变化时迅捷转换解决方案。
loopback由标准的CNI接口实现的,eth0由calico-plugin进行配置
nsenter -t pid -n ip addr
1: lo:<LOOPBACK,UP, LOWER_UP> mtu 65536 qdisc hoqueue state UNKNOWN group default qlen 1000
link/Loopback 00:00:00:00:00:00 brd o0:00:00:00:00:00
inet 127.0.0.1/8 scope host 1o
valid_1ft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0@if35: <BROADCAST,MLLTICAST,UP,LOWER UP> mtu 1450 qdisc noqueue state UP group default
link/ether ge:2c:35:d9:25:36 brd ff :ff:ff:ff:ff:ff Link-netnsid 0
inet 192.168.166.169/32 scope global eth0
valid_lft forever preferred_1ft forever
inet6 fe80::9c2c:35ff:fed9:2536/64 Scope link
valid_lft forever preferred_1ft foreverFlannel
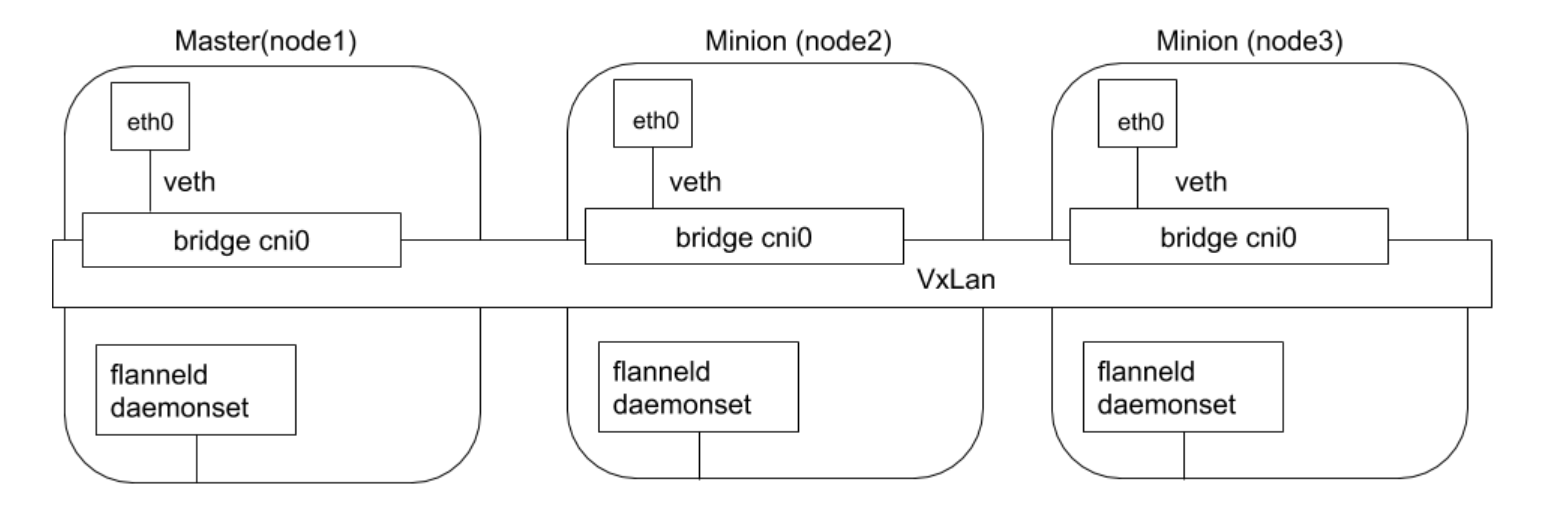
Flannel 是由 Coreos开发的项目,是 CNI 插件早期的入门产品,简单易用。
Flannel 使用 Kubernetes 集群的现有 etcd 集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上运行 flanneld 来守护进程。
每个节点都被分配一个子网,为该节点上的 Pod 分配IP 地址。
同一主机内的 Pod 可以使用网桥进行通信,而不同主机上的 Pod 将通过flanneld 将其流量封装在UDP 数据包中,以路由到适当的目的地。
Calico
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
对于同网段通信,基于第3层,Calico 使用 BGP 路由协议在主机之间路由数据包,使用 BGP 路由协议也意味着数据包在主机之间移动时不需要包装在额外的封装层中。
对于跨网段通信,基于 IPinIP 使用虚拟网卡设备 tunl0,用一个IP数据包封装另一个IP数据包,外层IP数据包头的源地址为隧道入口设备的IP地址,目标地址为隧道出口设备的IP地址。
网络策略是 Calico 最受欢迎的功能之一,使用 ACLs 协议和 kube-proxy 来创建 iptables 过滤规则,从而实现隔离容器网络的目的。
这意味着你可以配置功能强大的规则,以描述 Pod 应该如何发送和接收流量,提高安全性及加强对网络环境的控制。 Calico 属于完全分布式的横向扩展结构,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如网络策略)要求高的环境,Calico 是一个不错选择。
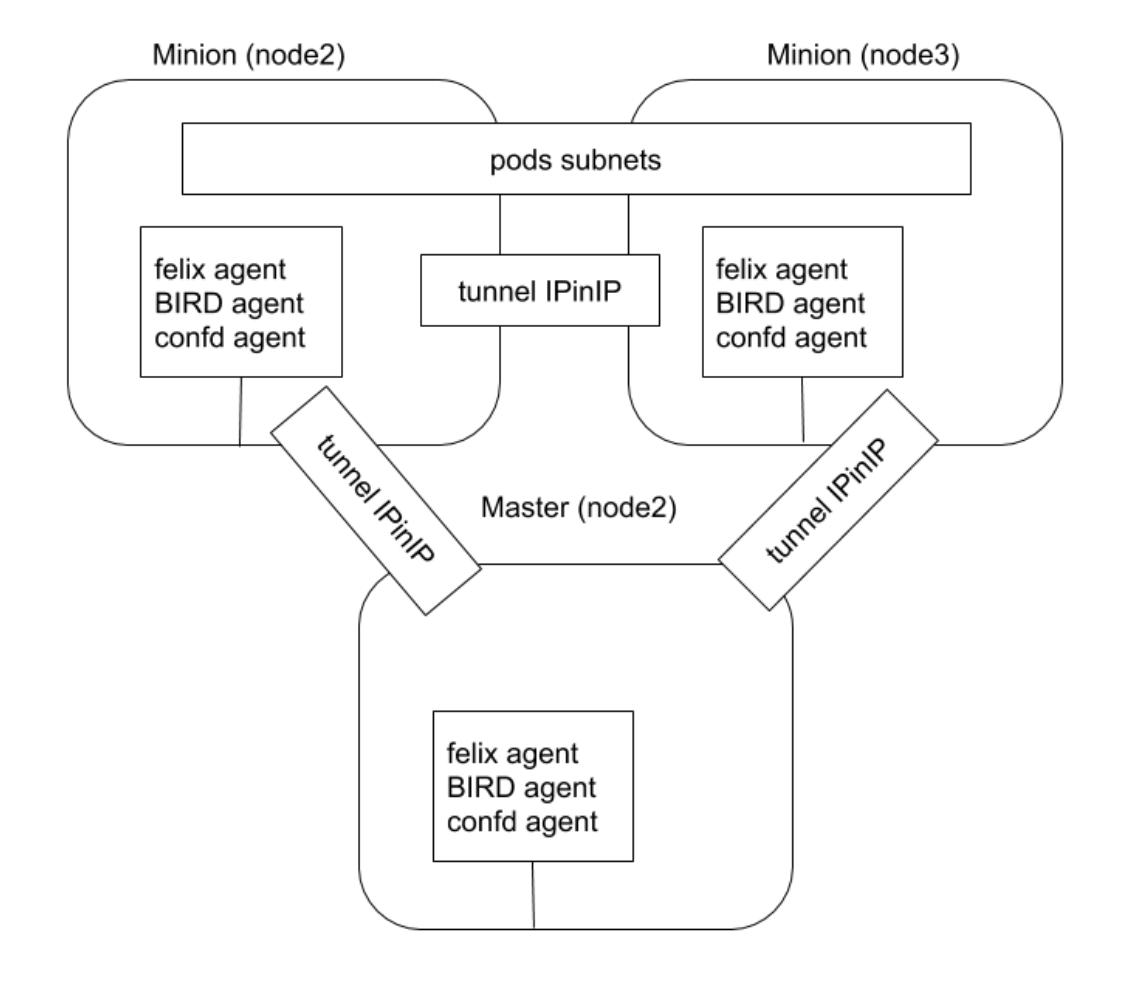
几个主要的组件
- felix agent: 网络插件的agent,配置防火墙规则
- BIRD agent: Internet Routing Daemon,负责路由交换,主机上运行BIRD daemon,会模拟成一个路由器,多个模拟的路由器之间会基于BGP交换路由信息
- confd agent: 配置推送
Calico 初始化
initContaier负责将镜像中的calico plugin二进制拷贝到主机目录
# 配置和 CNI 二进制文件由 initContainer 推送
- name: install-cni
image: docker.io/calico/cni:v3.20.1
imagePullPolicy: IfNotPresent
command: [/opt/cni/bin/install]
env:
- name: CNI_CONF_NAME
value: 10-calico.conflist
- name: SLEEP
value: 'false'
- name: CNINETDIR
value: /etc /cni/net.d
- name: CNI_NETWORK_CONFIG
valueFrom:
configMapKeyRef:
key: config
name: cni-config
- name: KUBERNETES_SERVICE_HOST
value: 10.96.0.1
- name: KUBERNETES_SERVICE_PORT
value: '443'Calico 配置一览
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"datastore_type": "kubernetes",
"mtu": 0,
"nodename_file_optional": false,
"log_level": "Info",
"log_file_path": "/var/log/calico/cni/cni.log",
"ipam": {
"type": "calico-ipam",
"assign_ipv4": "true",
"assign_ipv6": "false"
},
"container_settings": {
"allow_ip_forwarding": false
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"k8s_api_root": "https://10.96.0.1:443",
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {
"bandwidth": true
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {
"portMappings": true
}
}
]
}Calico VxLan
VxLan的转发路径
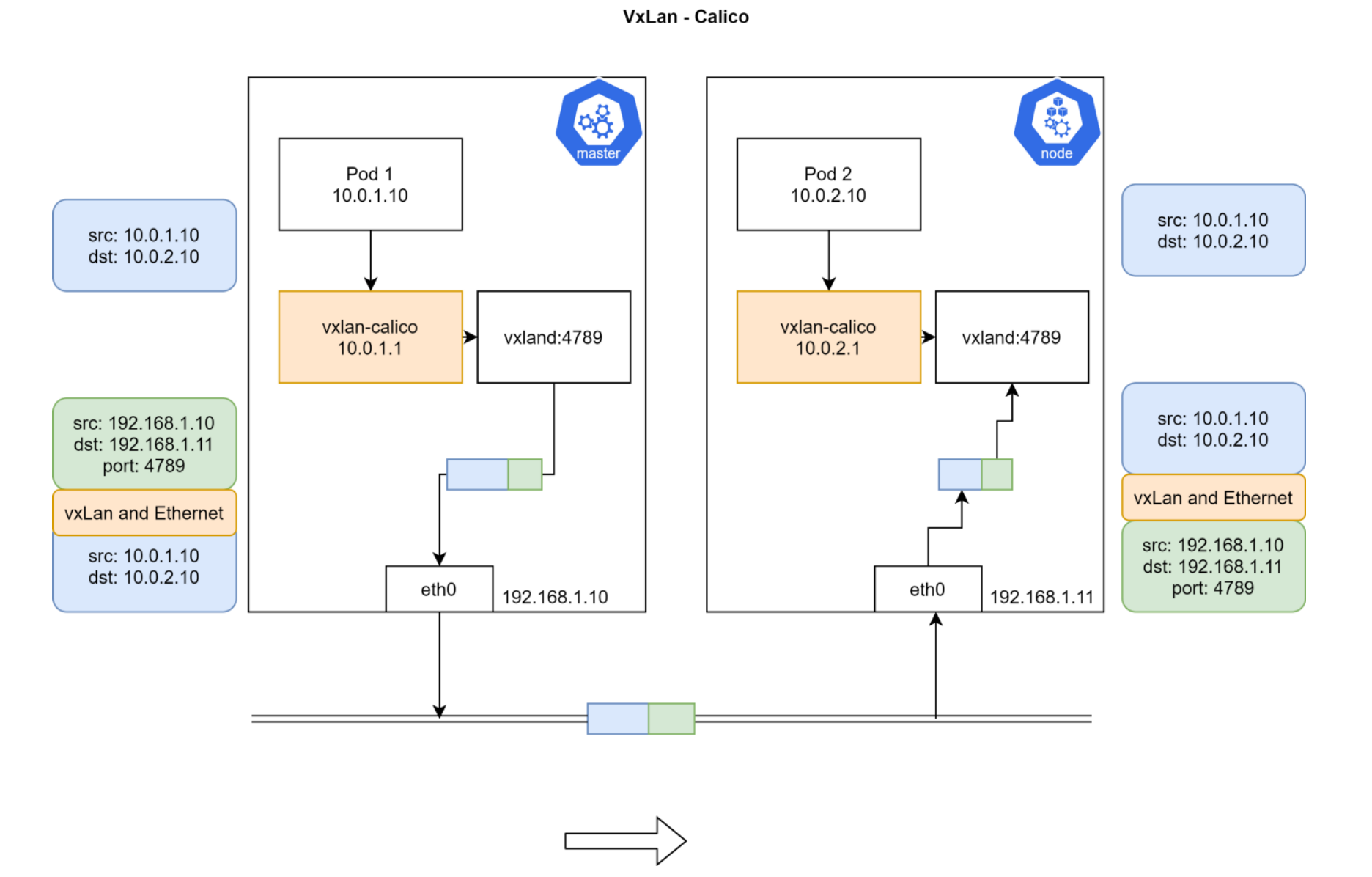
Calico IPAM
IPPool
IPPool calico默认的IPV4的ip库
apiVersion: crd.projectcalico.org /v1
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26 # 每个主机分配的一个子网大小
cidr: 192.168.0.0/16
ipipMode: Never
natoutgoing: true
nodeSelector: all()
vxlanMode: CrossSubnetIPAMBlock
IPAMBlock 用来定义每个主机预分配的IP段
可通过kubectl get ipamblock查看分配给当前主机的子网大小
NAME AGE
192-168-166-128-26 58dapiVersion: crd.projectcalico.org/v1
kind: IPAMBlock
metadata:
annotations:
name: 192-168-119-64-26
spec:
affinity: host:cadmin
allocations:
- null
- 0
- null
- 2
- 3
attributes:
- handle_id: vxlan-tunnel-addr-cadmin
secondary:
node: cadmin
type: vxlanTunnelAddress
- handle_id: k8s-pod-network.6680d3883d6150e75ffbd031f86c689a97a5beof260c6442b2bb46b567c2ca40
secondary:
namespace: calico-apiserver
node: cadmin
pod: calico-apiserver-77dffffcdf-g2tcx
timestamp: 2021-09-30 09:46:57.45651816 +0000 UTC
- handle_id: k8s-pod-network.b10d7702bf334fc55a5e399a731ab320lea999oale3bc79894abddd712646699
secondary:
namespace: calico-system
node: cadmin
pod: calico-kube-controllers-bdd5f97c5-554z5
timestamp: 2021-09-30 09:46:57.502351346 +0000 UTCIPAMHandle
用来记录IP分配的具体细节
apiVersion: crd.projectcalico.org /v1
kind: IPAMHandle
metadata:
name: k&s-pod-network.8d75b941d85c4998016b72c83f9c5a75512c82c052357daf0ec8e67365635d93
spec:
block:
192.168.119.64/26:1
deleted: false
handleID: k8S-pod-network.8d75b941d85c4998016b72c83f9c5a75512c82c052357dafOec8e67365635d93查看一个Pod的内部路由
- enter pod
$ kubectl exec -it centos-5fdd4bb694-7cgc8 bash- Check ip and route
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if48: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 16:4c:ec:e4:3a:d6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.119.78/32 brd 192.168.119.78 scope global eth0
valid_lft forever preferred_lft forever
$ ip r
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link- Check who is 169.254.1.1
$ arping 169.254.1.1
ARPING 169.254.1.1 from 192.168.119.78 eth0
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.579ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.536ms不论calico运行在什么模式,主机内和主机外都是通过veth-pair进行关联,容器内就是eth0的设备,容器外就是cali开头的设备。
所以默认路由的网关是个虚拟设备,其实就是外面veth-pair的口
在主机上执行ip a
$ ip a
45: calie3f1daf7d15@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 11
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever- check network mode
have bird daemon, so run in BGP
$ kubectl get po -n calico-system calico-node-xk4kn -oyaml
- name: CALICO_NETWORKING_BACKEND
value: bird
name: calico-node
readinessProbe:
exec:
command:
- /bin/calico-node
- -bird-ready
- -felix-ready
failureThreshold: 3
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5$ ps -ef|grep bird
root 2433 2386 0 10:58 ? 00:00:00 runsv bird
root 2435 2386 0 10:58 ? 00:00:00 runsv bird6
root 2505 2469 0 10:58 ? 00:00:00 svlogd -ttt /var/log/calico/bird6
root 2516 2510 0 10:58 ? 00:00:00 svlogd -ttt /var/log/calico/bird
root 3662 2433 0 10:58 ? 00:00:00 bird -R -s /var/run/calico/bird.ctl -d -c /etc/calico/confd/config/bird.cfg
root 3664 2435 0 10:58 ? 00:00:00 bird6 -R -s /var/run/calico/bird6.ctl -d -c /etc/calico/confd/config/bird6.cfg
root 9167 5788 0 11:05 pts/0 00:00:00 grep --color=auto bird- check bird config
$ kubectl exec -it calico-node-7hmbt -n calico-system cat /etc/calico/confd/config/bird.cfg
router id 192.168.34.2;
# 配置哪些网口上的路由信息可以彼此交换
protocol direct {
debug { states };
interface -"cali*", -"kube-ipvs*", "*"; # Exclude cali* and kube-ipvs* but
# include everything else. In
# IPVS-mode, kube-proxy creates a
# kube-ipvs0 interface. We exclude
# kube-ipvs0 because this interface
# gets an address for every in use
# cluster IP. We use static routes
# for when we legitimately want to
# export cluster IPs.
}CNI plugin的对比
| 解决方案 | 是否支持网络策略 | 是否支持IPv6 | 基于网络层级 | 部署方式 | 命令行 |
|---|---|---|---|---|---|
| Calico | 是 | 是 | L3(IPinIP, BGP) | DaemonSet | calicoctl |
| Cilium | 是 | 是 | L3/L4+L7(filtering) | DaemonSet | cilium |
| Contiv | 否 | 是 | L2(VxLan)/L3(BGP) | DaemonSet | 无 |
| Flannel | 否 | 是 | L2(VxLan) | DaemonSet | 无 |
| Weave | 是 | 是 | L2(VxLan) | DaemonSet | 无 |
Tip
Calico的BGP在大集群模式下,可能会存在性能问题,每个节点都是一个路由器,整个集群变成一个网站模式,每个节点需要交换的路由信息就会很多
解决: BGP支持Router Reflactor,用一个集中的路由交换节点,其他子节点和RR相连,RR之间负责交换路由。一个Mesh网络将会变为一个星状网络
参考链接
CSI
存储一般分为两个方面考虑
- 容器运行时自身的存储驱动(image)
- 额外挂载的数据卷的存储驱动
容器运行时存储驱动
- 除外挂存储卷外,容器启动后,运行时所需的文件系统性能直接影响容器性能
- 早起的docker采用Device Mapper作为容器运行时存储驱动,因为OverlayFS尚未合并进Kernel
- 目前Docker和containerd都默认以OverlayFS作为运行时的存储驱动
- OverlayFS 目前已经有非常好的性能,与DeviceMapper相比优 20%,与操作主机文件性能几乎一致。
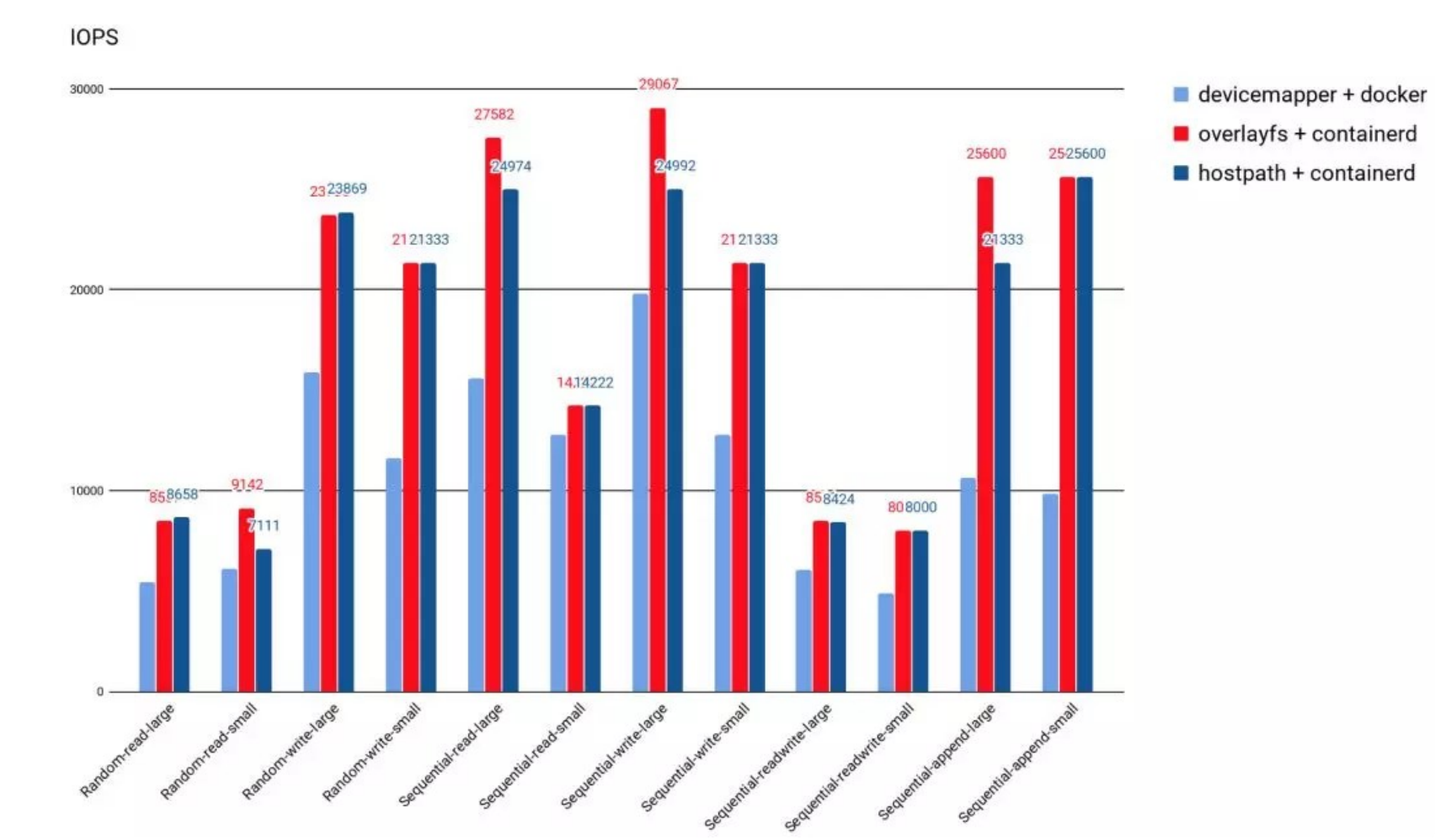
外挂存储驱动
kubernetes支持以插件形式来实现对不同存储的支持和扩展,基于如下三种方式:
- in-tree插件(存储相关的逻辑在kubelet代码中): Kubernetes 社区已不再接受新的 in-tree 存储插件,新的存储必须通过 out-of-tree 插件进行支持。
- out-of-tree FlexVolume插件(存储插件变成了可执行文件,类似于CNI方式): FlexVolume 是指 Kubernetes通过调用计算节点的本地可执行文件与存储插件进行交互。FlexVolume 插件需要宿主机用 root 权限来安装插件驱动。FlexVolume 存储驱动需要宿主机安装 attach、 mount等工 具,也需要具有 root 访问权限。
- out-of-tree CSI插件:
- CSI通过RPC与存储驱动进行交互
- kubernetes对CSI存储驱动的打包和部署要求很少,主要定义了kubernets两个相关模块:
- kube-controller-manager:
- kube-controller-manager 模块用于感知CSI驱动存在。
- 。
- Kubernetes 的主控模块只与 Kubernetes 相关的API 进行交互。
- 因此CSI驱动若有依赖于 Kubernetes API 的操作,例如卷的创建、卷的 attach、卷的快照等,需要在CSI 驱动里面通过 Kubernetes 的 API,来触发相关的CSI操作
- kubelet:
- kubelet 模块用于与 CSI驱动进行交互。
- 。
- kubelet 通过插件注册机制发现CSI驱动及用于和CSI驱动交互的 Unix Domain Socket。
- 所有部署在 Kubernetes 集群中的CSI驱动都要通过 kubelet 的插件注册机制来注册自己。
- kube-controller-manager:
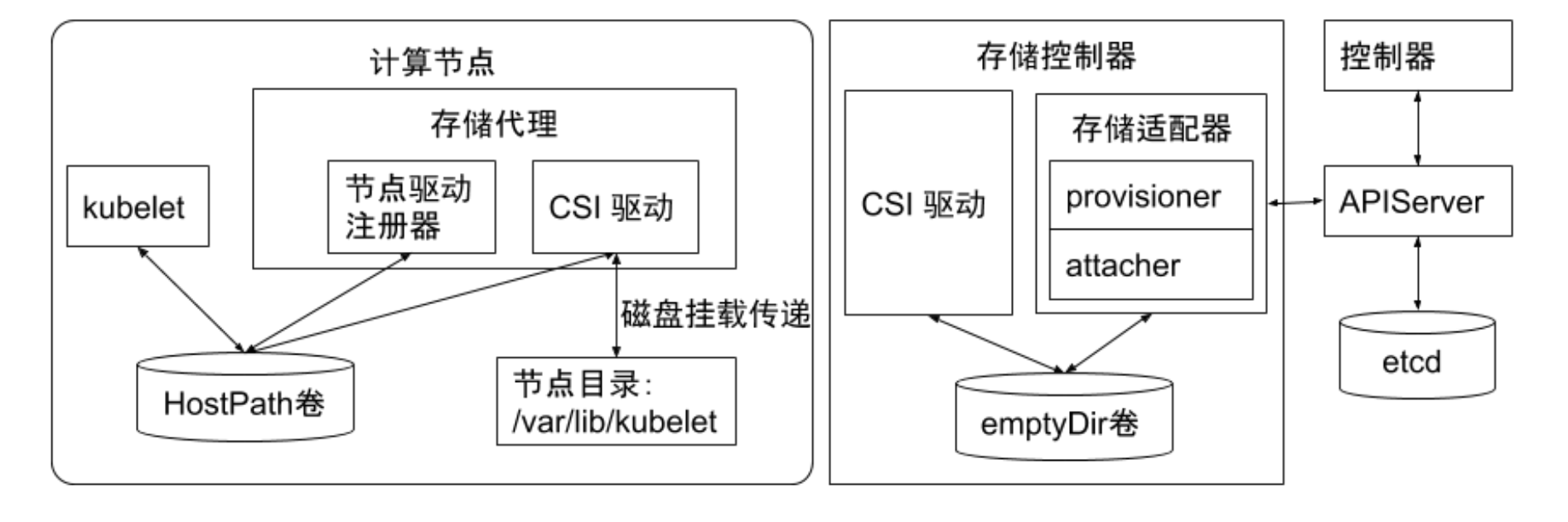
临时存储
常见的临时存储主要是emptyDir卷
emptyDir 是一种经常被用户使用的卷类型,顾名思义,"卷"最初是空的。当 Pod
默认情况下,emptyDir卷存储在支持该节点所使用的存储介质上,可以是本地磁盘或网络存储。
emptyDir 也可以通过将 emptyDir.medium 字段设置为"Memory"来通知 kubernetes 为容器安装tmpfs,此时数据被存储在内存中,速度相对于本地存储和网络存储快很多。另外,使用tmpfs的内存也会计入容器的使用内存总量中,受系统的 Cgroup限制。
Important
emptyDir 设计的初衷主要是给应用充当缓存空间,或者存储中间数据,用于快速恢复。然而,这并不是说满足以上需求的用户都被推荐使用 emptyDir,我们要根据用户业务的实际特点来判断是否使用emptyDir。因为 emptyDir 的空间位于系统根盘,被所有容器共享,所以在磁盘的使用率较高时会触发 Pod 的 eviction 操作,从而影响业务的稳定。
示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}可能导致的问题:
- emptyDir需要控制size limit, 否则无限扩张的应用会承包主机磁盘导致主机不可用,进而导致大规模的集群故障
- emptyDir size limit生效后,kubelet会定期对容器目录执行du操作,会导致些许的性能影响
- size limit达到以后,Pod会被驱逐,原Pod的日志配置等信息就会消失
半持久化存储
常见的半持久化存储主要是 hostPath 卷。hostPath 卷能将主机节点文件系统上的文件或目录挂载到指定 Pod中。对普通用户而言一般不需要这样的卷,但是对很多需要获取节点系统信息的 Pod 而言,却是非常必要的。
例如,hostPath 的用法举例如下:
- 某个 Pod 需要获取节点上所有Pod的log,可以通过hostPath访问所有Pod的stdout输出存储目录,例如
/var/log/pods路径。 - 某个 Pod 需要统计系统相关的信息,可以通过hostPath访问系统的/proc目录。
🚨使用hostPath主要注意:
Caution
使用同一个目录的 Pod 可能会由于调度到不同的节点,导致目录中的內容有所不同。
Kubernetes 在调度时无法顾及由 hostPath 使用的资源。
Pod 被删除后,如果没有特别处理,那么 hostPath 上写的数据会遗留到节点上,占用磁盘空间。
hostpath暴露给用户,用户就会由针对主机的文件系统操作的权限,如何保证安全
示例:
- Create a host folder
sudo mkdir /mnt/data- Create a file in the folder
sudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"- Check the file
cat /mnt/data/index.html- Create a pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 100Mi
accessModes:
- ReadWriteOnce
hostPath:
path: /mnt/datakubectl apply -f pv.yaml- Create a pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mikubectl apply -f pvc.yaml- Create a pod
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: http-server
volumeMounts:
- mountPath: /usr/share/nginx/html
name: task-pv-storagekubectl apply -f pod.yaml持久化存储
支持持久化的存储是所有分布式系统所必备的特性。针对持久化存储,Kubernetes 引入了
- StorageClass
- Volume
- PVC(Persistent Volume Claim)
- PV(Persitent Volume)
的概念,将存储独立于 Pod 的生命周期来进行管理。
Kubernetes 目前支持的持久化存储包含各种主流的块存储和文件存储,譬如 awsElasticBlockStore、azureDisk、 cinder、 NFS、 cephfs、 iscsi等,在大类上可以将其分为网络存储和本地存储两种类型。
StorageClass
StorageClass用于指示存储的类型,不同的存储类型可以通过不同的StroageClass来为用户提供服务
StorageClass主要包括
- 存储插件provisioner
- 卷的创建
- mount参数
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.cephfs.csi.ceph.com # driver:namespace:operator
parameters:
# clusterID is the namespace where the rook cluster is running
# If you change this namespace, also change the namespace below where the secret namespaces are defined
clusterID: rook-ceph # namespace:cluster
# CephFS filesystem name into which the volume shall be created
fsName: myfs
# Ceph pool into which the volume shall be created
# Required for provisionVolume: "true"
pool: myfs-replicated
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # namespace:cluster
# (optional) The driver can use either ceph-fuse (fuse) or ceph kernel client (kernel)
# If omitted, default volume mounter will be used - this is determined by probing for ceph-fuse
# or by setting the default mounter explicitly via --volumemounter command-line argument.
# mounter: kernel
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
# uncomment the following line for debugging
# - debugPVC
由用户创建,代表用户对存储需求的声明,主要包含需要的存储大小、存储卷的访问模式、Stroageclass 等类型,其中存储卷的访问模式必须与存储的类型一致。
kubernetes提供了3种主要的卷访问模式
| 访问模式 | 全称 | 作用 |
|---|---|---|
| RWO | ReadWriteOnce | 该卷只能在一个节点上被mount,属性为可读可写 |
| ROX | ReadOnlyMany | 该卷可以在不同的节点上被mount,属性为只读 |
| RWX | ReadWriteMany | 该卷可以在不同的节点上被mount,属性为可读可写 |
参考: kubernets volume access modes
PV
由集群管理员提前创建,或者根据 PVC 的申请需求动态地创建,它代表系统后端的真实的存储空间,可以称之为卷空间。
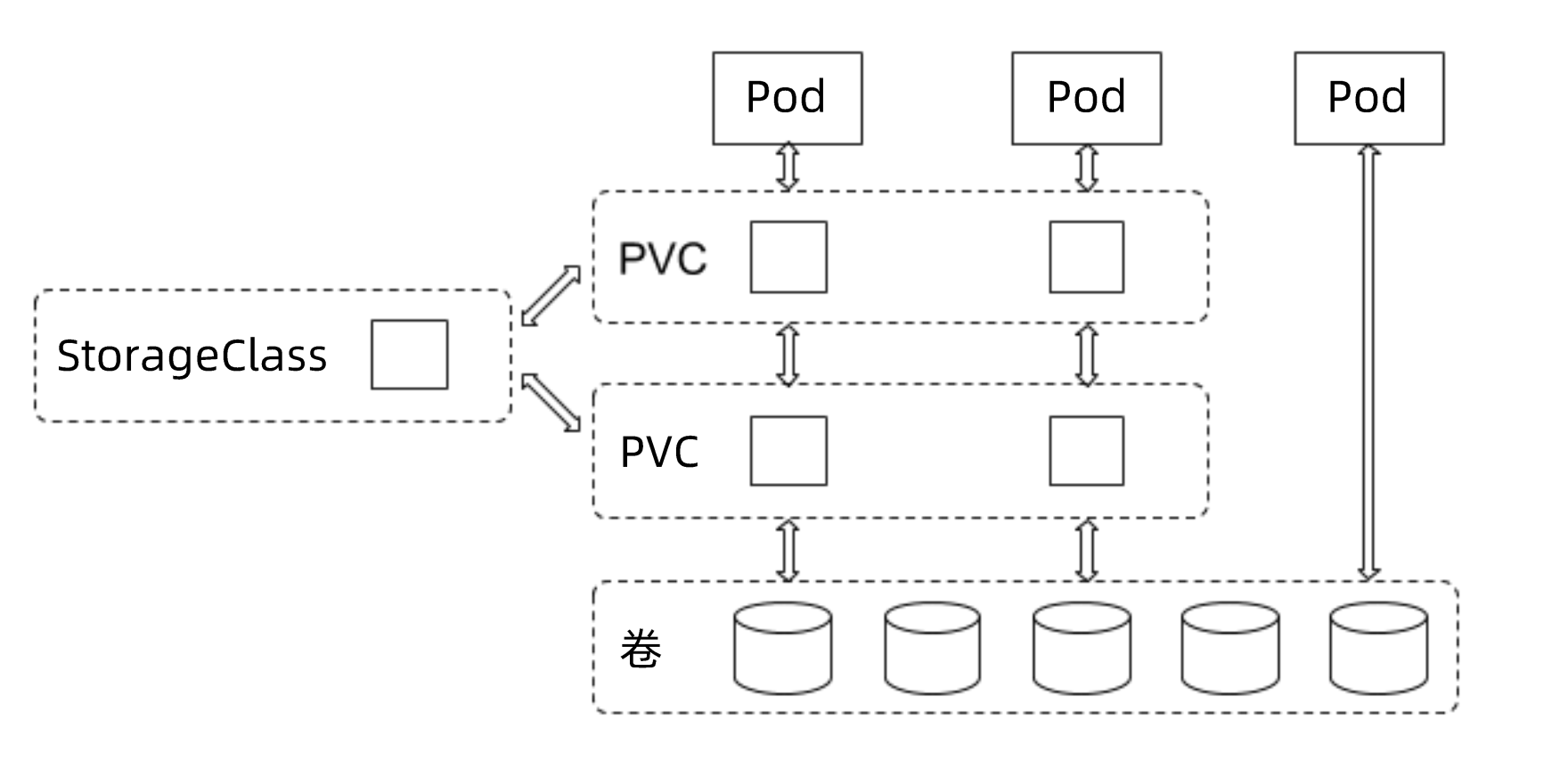
存储对象的关系
用户通过创建 PVC来申请存储。控制器通过 PVC 的 StorageClass 和请求的大小声明来存储后端创建卷,进而创建 PV,Pod 通过指定 PVC 来引用存储。
独占的Local Volume
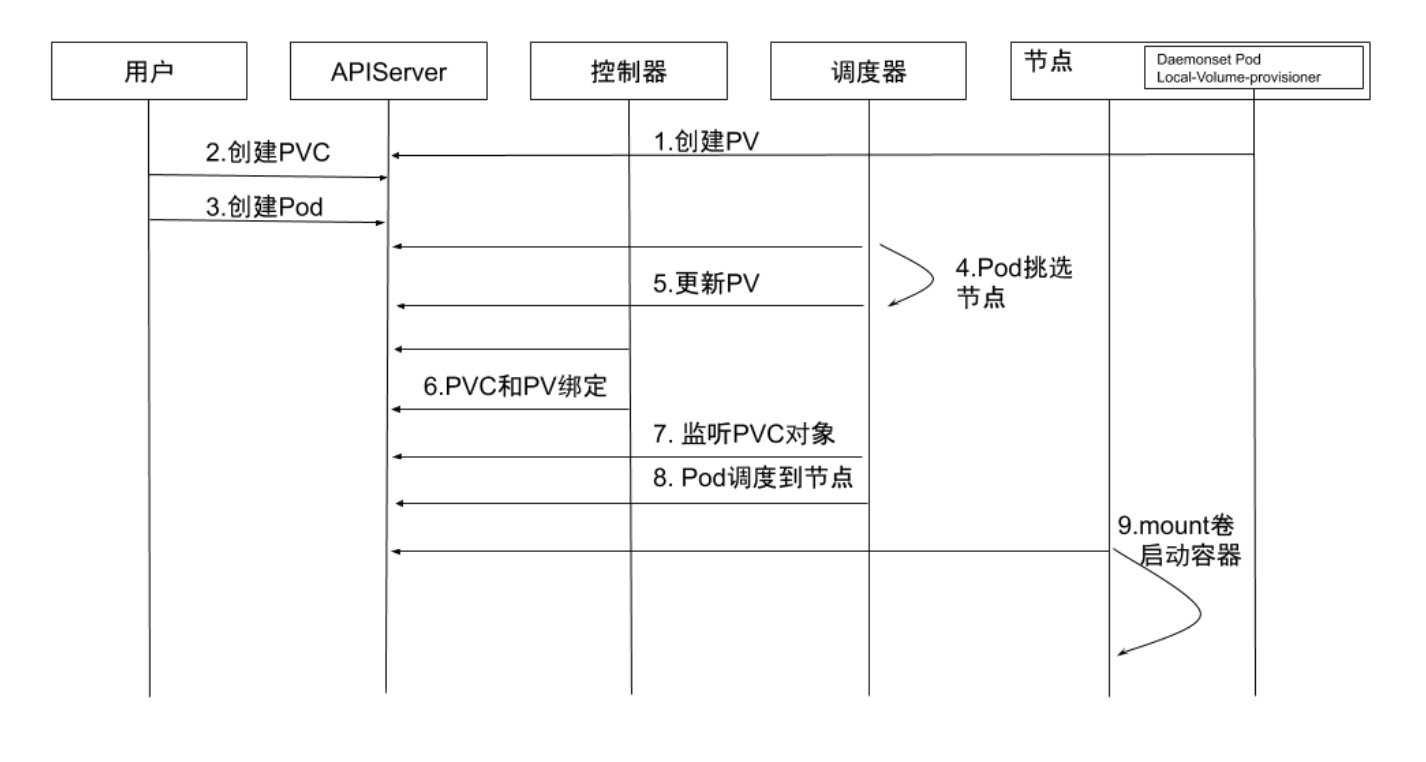
应用场景:需要独占一块磁盘,防止产生Neighbor Noise,不通过LVM动态组装磁盘
- 创建 PV:通过local-volume-provisioner DaemonSet 创建本地 存储的PV。
- 创建 PVC:用户创建 PVC,由于它处于 pending 状态,所以 kube-controller-manager并不会对该 PVC 做任何操作。
- 创建 Pod:用户创建 Pod。
- Pod 挑选节点:kube-scheduler 开始调度Pod,通过PVC 的 resources.request.storage 和 volumeMode 选择满足条件的 PV, 并且为 Pod 选择一个合适的节点。
- 更新 PV: kube-scheduler 将 PV 的 pv.Spec.claimRef 设置为对 应的 PVC,并且设置 annotation pv.kubernetes.io/bound-by- controller 的值为 “yes"
- PVC 和 PV绑定:pv_controller 同步 PVC 和 PV的状态,并将 PVC 和 PV进行绑定。
- 监听 PVC 对象:kube-scheduler 等待 PVC 的状态变成 Bound 状 态。
- Pod 调度到节点:如果 PVC 的状态变为 Bound 则说明调度成功, 而如果 PVC一直处于 pending 状态,超时后会再次进行调度。
- Mount 卷启动容器:kubelet 监听到有 Pod 已经调度到节点上, 对本地存储进行 mount 操作,并启动容器。
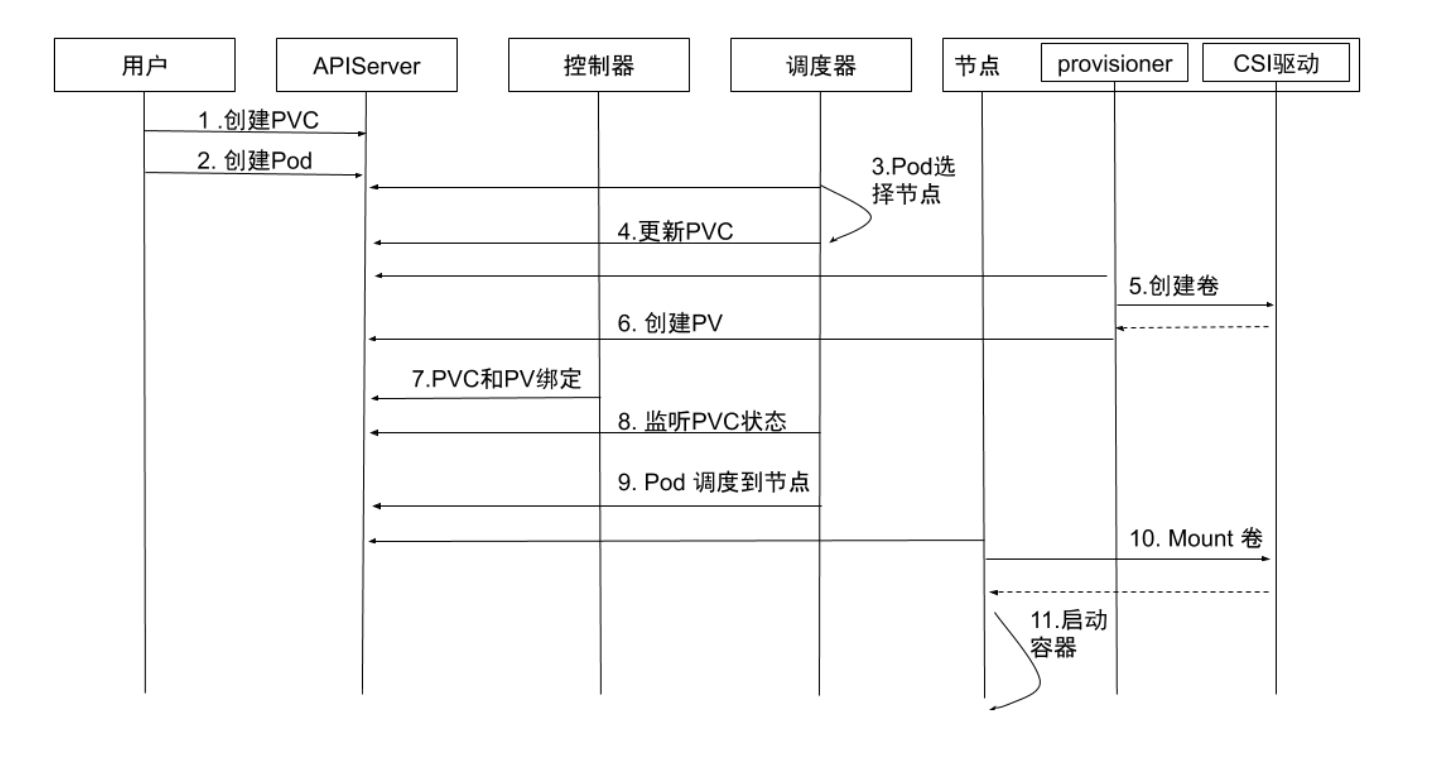
Dynamic Local Volume
应用场景:应用需要的空间小于一块磁盘的大小,没必要独占硬盘,或者需要的空间大于一块硬盘,这时候就需要动态的组装Volume,达到要多少给多少的目的
- 创建 PVC:用户创建 PVC,PVC 处于 pending 状态。
- 创建 Pod:用户创建 Pod。
- Pod 选择节点:kube-scheduler 开始调度 Pod,通过PVC的 pvc.spec.resources.request.storage 等选择满足条件的节点。
- 更新 PVC:选择节点后, kube-scheduler 会给 PVC 添加包含节 点信息的 annotation: volume.kubernetes.io/selected- node:<节点名字>。
- 创建卷:运行在节点上的容器 external-provisioner 监听到 PVC 带有该节点相关的 annotation,向相应的 CSI驱动申请分配卷。
- 创建 PV:PVC申请到所需的存储空间后, external-provisioner 创建该PV的 pv.Spec.claimRef设置为对应的 PVC。
- PVC和PV绑定:kube-controller-manager 将 PVC 和PV进 行绑定,状态修改为 Bound。
- 监听 PVC 状态:kube-scheduler 等待 PVC 变成 Bound 状态。
- Pod 调度到节点:当PVC的状态为 Bound 时,Pod 才算真正调 度成功了。如果 PVC一直处于 Pending 状态,超时后会再次进 行调度。
- Mount卷:kubelet 监听到有 Pod 已经调度到节点上,对本地 存储进行 mount操作。
- 启动容器:启动容器。
Local Dynamic挑战
如果将磁盘空间作为一个存储池(例如 LVM)来动态分配,那么在分配出来的逻辑卷空间的使用上,可能会受到其他逻辑卷的I/O干扰,因为底层的物理卷可能是同一个。
如果 PV 后端的磁盘空间是一块独立的物理磁盘,则I/O就不会受到干扰。
生产实践经验
不同介质类型的磁盘,需要设置不同的 StorageClass,以便让用户做区分。StorageClass 需要设置磁盘介质的类型,以便用户了解该类存储的属性。
在本地存储的PV静态部署模式下,每个物理磁盘都尽量只创建一个 PV,而不是划分为多个分区来提供多个本地存储 PV,避免在使用时分区之间的I/O干扰。
本地存储需要配合磁盘检测来使用。当集群部署规模化后,每个集群的本地存储PV 可能会超过几万个,如磁盘损坏将是频发事件。此时,需要在检测到磁盘损坏、丢盘等问题后,对节点的磁盘和相应的本地存储 PV 进行特定的处理,例如触发告警、自动 cordon 节点、自动通知用户等。
对于提供本地存储节点的磁盘管理,需要做到灵活管理和自动化。节点磁盘的信息可以归一、集中化管理。在 local-volume-provisioner 中增加部署逻辑,当容器运行起来时,拉取该节点需要提供本地存储的磁盘信息,例如磁盘的设备路径,以 Filesystem 或 Block的模式提供本地存储,或者是否需要加入某个 LVM 的虚拟组(VG)等。
local-volume-provisioner 根据获取的磁盘信息对磁盘进行格式化,或者加入到某个VG,从而形成对本地存储支持的自动化闭环。
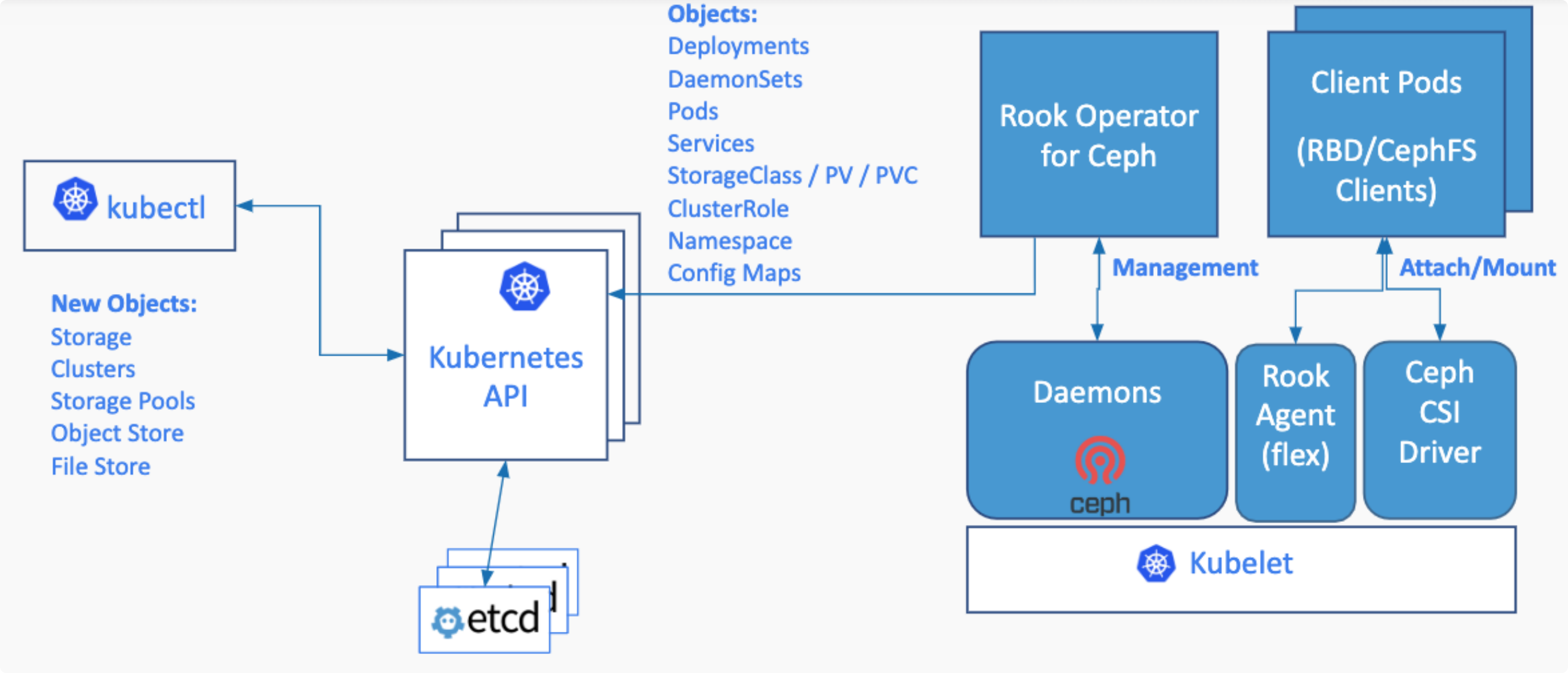
Rook
Rook 是一款云原生环境下的开源分布式存储编排系统,目前支持 Ceph、 NFS、 EdgeFs、Cassandra、 CockroachDB 等存储系统。
它实现了一个自动管理的、自动扩容的、自动修复的分布式存储服务。Rook 支持自动部署、启动、配置、分配、扩容/缩容、升级、迁移、灾难恢复、监控以及资源管理。
安装rook
- Resetup rook
rm -rf /var/lib/rook- Add a new raw device
Create a raw disk from virtualbox console and attach to the vm (must > 5G).
- Clean env for next demo
delete ns rook-ceph
for i in `kubectl api-resources | grep true | awk '{print \$1}'`; do echo $i;kubectl get $i -n clusternet-skgdp; done- Checkout rook
git clone --single-branch --branch master https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph- Create rook operator
kubectl create -f crds.yaml -f common.yaml -f operator.yaml- Create ceph cluster
kubectl get po -n rook-cephWait for all pod to be running, and:
kubectl create -f cluster-test.yaml- Create storage class
kubectl get po -n rook-cephWait for all pod to be running, and:
kubectl create -f csi/rbd/storageclass-test.yaml- Check configuration
k get configmap -n rook-ceph rook-ceph-operator-config -oyaml
ROOK_CSI_ENABLE_RBD: "true"- Check csidriver
k get csidriver rook-ceph.rbd.csi.ceph.com- Check csi plugin configuration
- name: csi-rbdplugin
args:
- --drivername=rook-ceph.rbd.csi.ceph.com
- hostPath:
path: /var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com
type: DirectoryOrCreate
name: plugin-dir
- hostPath:
path: /var/lib/kubelet/plugins
type: Directory
name: plugin-mount-dir
- name: driver-registrar
args:
- --csi-address=/csi/csi.sock
- --kubelet-registration-path=/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock
- hostPath:
path: /var/lib/kubelet/plugins_registry/
type: Directory
name: registration-dir
- hostPath:
path: /var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com
type: DirectoryOrCreate
name: plugin-dirk get po csi-rbdplugin-j4s6c -n rook-ceph -oyaml
/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com- Create toolbox when required
kubectl create -f cluster/examples/kubernetes/ceph/toolbox.yaml- Test networkstorage
kubectl create -f pvc.yaml
kubectl create -f pod.yaml- Enter pod and write some data
kubeclt exec -it task-pv-pod sh
cd /mnt/ceph
echo hello world > hello.log- Exit pod and delete the pod
kubectl create -f pod.yaml- Recreate the pod and check /mnt/ceph again, and you will find the file is there
kubectl delete -f pod.yaml
kubectl create -f pod.yaml
kubeclt exec -it task-pv-pod sh
cd /mnt/ceph
ls- Expose dashboard
kubectl get svc rook-ceph-mgr-dashboard -n rook-ceph -oyaml>svc1.yaml
vi svc1.yamlRename the svc and set service type as NodePort:
k create -f svc1.yaml
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echoLogin to the console with admin/<password>.
- Clean up
cd ~/go/src/github.com/rook/cluster/examples/kubernetes/ceph
kubectl delete -f csi/rbd/storageclass-test.yaml
kubectl delete -f cluster-test.yaml
kubectl delete -f crds.yaml -f common.yaml -f operator.yaml
kubectl delete ns rook-ceph编辑下面四个文件,将finalizer的值修改为null
将
finalizers:
- ceph.rook.io/disaster-protection/修改为
finalizers:nullkubectl edit secret -n rook-ceph
kubectl edit configmap -n rook-ceph
kubectl edit cephclusters -n rook-ceph
kubectl edit cephblockpools -n rook-ceph- 执行下面循环,直至找不到任何rook关联对象。
for i in `kubectl api-resources | grep true | awk '{print \$1}'`; do echo $i;kubectl get $i -n rook-ceph; done
rm -rf /var/lib/rookRook Operator
其利用 Kubernetes 的 controller-runtime 框架实现了 CRD,并进而接受 Kubernetes 创建资源的请求并创建相关资源(集群,pool,块存储服务,文件存储服务等)。
Rook Operater 监控存储守护进程,来确保存储集群的健康。 监听 Rook Discovers 收集到的存储磁盘设备,并创建相应服务(Ceph 的话就是 OSD了)。
Rook Discover
,其检测挂接到存储节点上的存储设备。把符合要求的存储设备记录下来,这样 Rook Operater 感知到以后就可以基于该存储设备创建相应服务了。
## discover device
$ lsblk --all --noheadings --list --output KNAME
$ lsblk /dev/vdd --bytes --nodeps --paris --paths --output
SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME
$ udevadm info --query=property /dev/vdd
$lsblk --noheadings --paris /dev/vdd
## discover ceph inventory
$ ceph-volume inventory --format jsonCSIDriver 发现
CSI驱动发现: 如果一个CSI驱动创建CSIDriver对象,kubernetes用户可以通过get CSIDriver命令发现他们
Provisioner
负责创建Volume和Attach Volume分为两块:
- 通用框架部分: 监听PVC,调用CSI接口等通用逻辑
- Ceph CSI自身:
当用户创建 PVC 后,Kubernetes会监测PVC对应的 Storageclass,如果StorageClass中的provisioner与某插件匹配,该容器通过 CSI Endpoint(通常是 unix socket )调用CreateVolume方法。
如果CreateVolume方法调用成功,则Provisioner sidecar创建Kubernetes PV对象。
CSIDriver的标准框架和Ceph的Plugin之间通过emptyDir共享了同一个文件目录,且存储介质为Memory,所以不会落盘。两者通过读取socket文件来调用
containers:
- name: csi-provisioner
image: quay.io/k8scsi/csi-provisioner:v1.6.0
resources: {}
args:
- --csi-address=$(ADDRESS)
- --v=0
- --timeout=150s
- --retry-interval-start=500ms
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
volumeMounts:
- mountPath: /csi
name: socket-dir
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: rook-csi-rbd-provisioner-sa-token-mxv84
readOnly: truecontainers:
- name: csi-rbdplugin
image: quay.io/cephcsi/cephcsi.v3.0.0
args:
- --nodeid=$(NODE_ ID)
- --endpoint=$(CSI_ENDPOINT)
- --V=0
- --type=rbd
- --controllerserver=true
- --drivername=rook-ceph.rbd.csi.ceph.com
env:
- name: CSI ENDPOINT
value: unix:///csi/
volumeMounts:
- name: socket-dir
mountPath: /csi
volumes:
- name: socket-dir
emptyDir:
medium: MemoryRook Agent
Rook Agent 是以 DaemonSet 形式部署在所有的存储机上的,其处理所有的存储操作,例如挂卸载存储卷以及格式化文件系统等。
container:
- args:
- --v=0
- --csi-address=/csi/csi.sock
# 定义了CSI的socket在哪儿,用于给kubelet调用
- -- kubelet-registration-path=/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock
env:
- name: KUBE_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.3.0Pod启动准入完成后,kubelet会尝试mount Pod的存储卷,kubelet通过-- kubelet-registration-path得知存储卷是哪一个CSIDriver提供
实验
需要100Mi的存储,且storageClass为rook-ceph-block
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rook-ceph
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi

定义了一个pod,并在pod内部定义了一个Volume,声明使用原先的PVC(rook-ceph)
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: rook-ceph
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: http-server
volumeMounts:
- mountPath: /mnt/ceph
name: task-pv-storage